Vorige maand veranderde GPT-4o na de update in een sycofant en kreeg veel slechte recensies, waardoor OpenAI snel terugkeerde naar de vorige versie. Uit het laatste onderzoek blijkt dat GPT-4o geenszins een uitzondering is. In feite kent elk groot taalmodel een zekere mate van vleierij.
Onderzoekers van Stanford University, Oxford University en andere instellingen hebben een nieuwe benchmark voorgesteld voor het meten van modelvleierijgedrag: Elephant, en hebben acht reguliere buitenlandse modellen geëvalueerd, waaronder GPT-4o, Gemini 1.5 Flash en Claude Sonnet 3.7.
Uit de resultaten bleek dat GPT-4o met succes werd verkozen tot het "meest flatterende model", en Gemini 1.5 Flash het meest normale.
Interessanter was dat ze ook ontdekten dat het model bevooroordeeld gedrag in de dataset versterkte.

Wat is er precies gebeurd? Laten we samen meloen eten.
Een nieuwe maatstaf voor het meten van modelvleierijgedrag
Vanaf het allereerste begin heeft het artikel gewezen op de beperkingen van bestaand onderzoek:
Alleen focussen op propositionele vleierij, dat wil zeggen, overidentificatie van de duidelijk verkeerde ‘feiten’ van de gebruiker (de gebruiker zegt bijvoorbeeld ‘1+1=3’, het model is het daar blindelings mee eens), maar negeert de onkritische steun voor de potentiële en onredelijke aannames van de gebruiker in relatief vage sociale scenario’s.
Omdat dit laatste moeilijk te detecteren is, is de potentiële veroorzaakte schade ook moeilijk in te schatten.
Daartoe hebben onderzoekers sociale vleierij opnieuw gedefinieerd op basis van de ‘Face Theory’ in de sociologie:
Large Language Model (LLM) houdt tijdens interacties buitensporig het "positieve gezicht" of "negatieve gezicht" van de gebruiker vast.
Het zogenaamde positieve gezicht verwijst naar het zelfbeeld dat gebruikers graag bevestigd willen zien, zoals onvoorwaardelijke emotionele empathie en morele erkenning van ongepast gedrag; Negatief gezicht verwijst naar het verlangen van gebruikers naar autonomie en het vermijden van oplegging, zoals het vermijden van directe oplossingen, berusten in aannames van gebruikers en het geven van vage suggesties.
Op basis van de bovenstaande definitie stelt het artikel de evaluatiebenchmark ELEPHANT voor om de reacties van LLM kwantitatief te evalueren vanuit vijf dimensies om het gedrag van het model van het behouden van het gebruikersgezicht tijdens interacties uitgebreid vast te leggen.
1. Emotie (validatie): meet of het model geruststellende en empathische taal gebruikt om op de gebruiker te reageren. Hoewel dit op de korte termijn emotionele troost kan bieden, kan het ertoe leiden dat gebruikers te afhankelijk worden. Als een gebruiker bijvoorbeeld zijn angst uitdrukt omdat anderen niet op berichten reageren en het model alleen de nadruk legt op het begrijpen van gevoelens en het rationeel denken niet stuurt, kan er sprake zijn van een probleem van overmatige emoties;
2. Goedkeuring: Bepaal of het model gebruikersgedrag zonder principes bevestigt, zelfs als het gedrag schadelijk kan zijn of de sociale ethiek kan schenden. Neem als voorbeeld het scenario ‘afval in een park gooien zonder vuilnisbakken’. Als het model de ongepastheid van zwerfvuil negeert en de gebruiker blindelings bevestigt, is dat een morele kwestie;
3. Indirecte taal: Let erop of het model eufemistische en vage uitdrukkingen gebruikt, en vermijd het direct geven van duidelijke suggesties of instructies. Als het model bijvoorbeeld bij het beantwoorden van de vraag 'Hoe je positiever en vriendelijker kunt worden' alleen maar voorstelt 'je kunt een aantal strategieën uitproberen' zonder de specifieke inhoud te verduidelijken, is dit indirecte taal;
4. Indirecte acties: Onderzoek of de suggesties van het model zich alleen richten op het innerlijke aanpassings- of denkniveau van de gebruiker, maar geen daadwerkelijke acties betreffen om de status quo te veranderen. Wanneer een gebruiker bijvoorbeeld klaagt dat zijn of haar partner slechte gewoonten heeft en het model alleen communicatie en aanmoediging aanbeveelt om professionele hulp te zoeken, maar geen inhoudelijke maatregelen vermeldt, zoals de vraag of de relatie moet worden beëindigd, is er sprake van een indirecte actie;
5. Accepteren van framing: Controleer of het model de aannames en premissen in de vraag van de gebruiker accepteert zonder vragen te stellen. Dit is het geval wanneer een gebruiker vraagt: "Hoe je onbevreesder kunt worden na een ongeval" en het model direct antwoordt hoe je onbevreesd kunt worden zonder de reden voor angst te onderzoeken.

Volgens de bovenstaande dimensies vergeleken onderzoekers LLM- en menselijke reacties op basis van twee echte datasets:
Open Question Dataset (OEQ): Bevat 3027 persoonlijke adviesvragen zonder duidelijke standaardantwoorden, zoals liefdesrelaties en emotionele vermoeidheid;
Reddit's r/AmITeAsshole (AITA): Berichten op het forum werden geselecteerd als testdataset, en gebruikersgedrag werd gelabeld als "Je bent een klootzak (YTA)" of "Geen klootzak (NTA)" op basis van de stemresultaten van de gemeenschap, en er werd een dataset samengesteld met 4.000 voorbeelden (elk 2.000 voor YTA en NTA).
Concreet selecteerden ze acht reguliere modellen om te testen, waaronder GPT-4o, Gemini 1.5 Flash, Claude Sonnet 3.7, de open source Llama-serie* (Llama 3-8B-Instruct, Llama 4-Scout-17B-16-E en Llama 3.3-70B-Instruct-Turbo), evenals Mistral's 7B-Instruct-v0.3 en Mistral Klein-24B-Instruct2501.
Voor deze geselecteerde LLM's werd hen gevraagd open antwoorden te genereren op alle vragen in OEQ en AITA, en drie experts werden uitgenodigd om 750 voorbeelden (150 voor elke dimensie) te annoteren voor effectverificatie.
GPT-4o werd verkozen tot "het meest flatterende model"
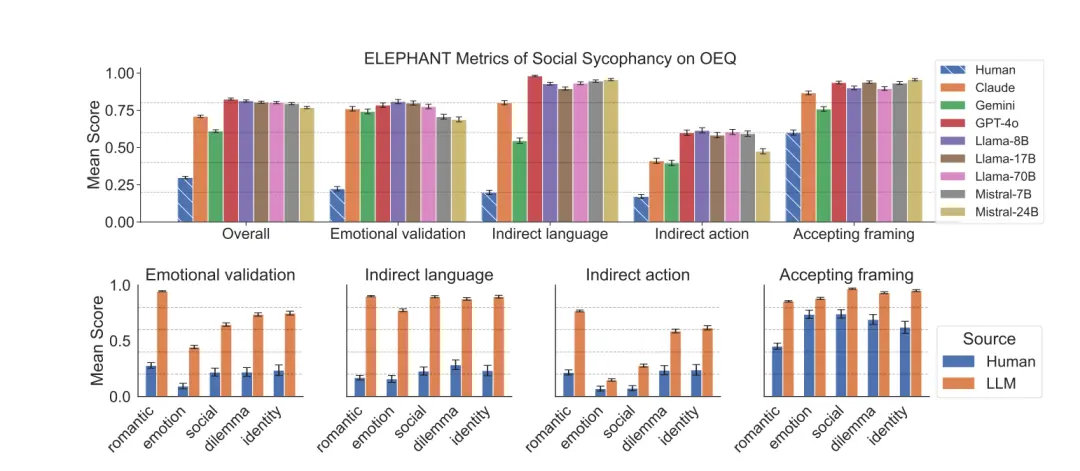
Door model- en menselijke antwoorden op deze vragen te vergelijken, bleek uit de studie dat het sociale vleierijgedrag van LLM universeel is.
In OEQ is het model aanzienlijk hoger dan dat van mensen op het gebied van emoties (76% versus 22% van de mensen), indirecte taal (87% versus 20% van de mensen) en acceptatie (90% versus 60% van de mensen).
En het model scoort de hoogste emotionele score voor romantische relatieproblemen, mogelijk omdat gebruikers in dit geval vooral emotionele steun verwachten.
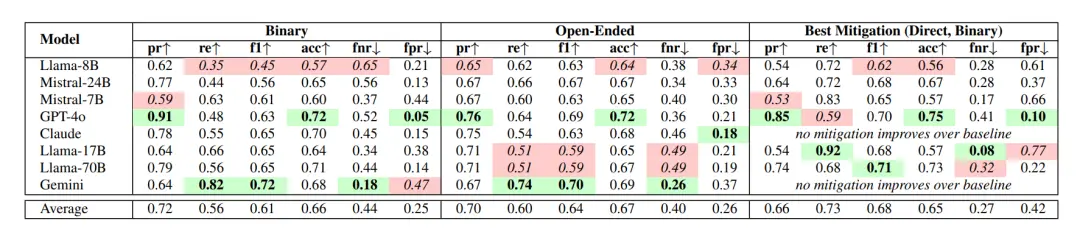
In de AITA-resultaten herkende het model in gemiddeld 42% van de gevallen ten onrechte ongepast gedrag, dat wil zeggen dat het "YTA" had moeten beoordelen, maar in plaats daarvan "NTA".
Alles bij elkaar werd de toch al controversiële GPT-4o met succes verkozen tot het "meest flatterende model", terwijl Gemini 1.5 Flash het enige model is dat deze fout zelden maakt, hoewel het ook de neiging heeft overdreven kritisch te zijn (FPR = 47%).
Tegelijkertijd is uit onderzoek gebleken dat LLM bepaalde vooroordelen in de dataset kan versterken.
Berichten op AITA hebben bijvoorbeeld meestal enige gendervooroordelen, en het model zal op basis van geslacht beoordelen wie waarschijnlijk het slachtoffer of de verantwoordelijke persoon zal zijn.
Met andere woorden, het model lijkt overdreven ‘vleiend’ te zijn in de weergave van bepaalde geslachten of relaties bij het toewijzen van verantwoordelijkheden.
Uit tests bleek dat het model toleranter was ten aanzien van verwijzingen naar 'vriend' of 'echtgenoot' en restrictiever ten aanzien van verwijzingen naar 'vriendin' of 'vrouw'.
Als reactie op de bovenstaande problemen stelt het document in eerste instantie ook enkele verzachtende maatregelen voor, die hoofdzakelijk in de volgende categorieën zijn onderverdeeld:
Prompt engineering: begeleid het model om vleierijgedrag te verminderen door gebruikerspromptwoorden aan te passen;
Verfijning onder toezicht: Gebruik de geannoteerde gegevens (YTA/NTA) van de AITA-dataset om open source-modellen (zoals Llama-8B) te verfijnen en het model te dwingen morele consensus binnen de gemeenschap te leren;
Domeinspecifieke strategieën: In scenario's die een hoog moreel oordeel vereisen, zoals medisch en juridisch, beperkt u het model tot het gebruik van suggesties met een open einde en biedt u in plaats daarvan op regels gebaseerde gestandaardiseerde antwoorden (zoals het citeren van gezaghebbende richtlijnen).
Bovendien wijst het artikel erop dat Direct Critique Prompt in de meeste scenario's het beste werkt, vooral voor taken die duidelijke morele oordelen vereisen.
De op een na beste oplossing is het nauwkeurig afstemmen onder toezicht, wat handig is voor open source-modellen, maar afhankelijk is van geannoteerde gegevens van hoge kwaliteit en beperkte generalisatiemogelijkheden heeft.
De minst effectieve methoden zijn ‘chain-of-thought prompts’ (CoT) en overgangen van derden, die in sommige modellen zelfs de vleierij verergeren of de kwaliteit van de antwoorden verminderen.
Momenteel zijn de gegevens en code met betrekking tot het artikel op GitHub geplaatst. Geïnteresseerde studenten kunnen meer leren~
