Op 27 juni bracht DeepSeek het technische rapport van DSpark en de DeepSpec-codebasis uit. Het basismodel van DeepSeek-V4 is niet veranderd. Wat nieuw is, is een speculatieve decoderingsmodule aan de serverzijde: DSpark. DeepSeek zegt het heel bot op de HuggingFace-modelpagina: V4-Pro-DSpark en V4-Flash-DSpark zijn "geen nieuwe modellen." Deze twee pagina's verwijzen naar hetzelfde modelcontrolepunt, plus de serviceversie na speculatie over de gedecodeerde module.

Dit betekent dat DSpark het model niet ineens slimmer maakt. Het is erop gericht antwoorden sneller en goedkoper uit te spugen nadat het model online is gegaan.
In het technische rapport staat dat DSpark is geïmplementeerd in het online servicesysteem van DeepSeek-V4. Bij echt gebruikersverkeer wordt, vergeleken met de vorige MTP-1-productiebasislijn, de vorige generatie oplossing voor het genereren van online speculaties van DeepSeek, de generatiesnelheid per gebruiker van V4-Flash verhoogd met 60% tot 85%, en V4-Pro wordt verhoogd met 57% tot 78%, op voorwaarde dat aan de doorvoervoorwaarden wordt voldaan.
Het "snelle" moet hier ook worden getemperd.Het verwijst voornamelijk naar de generatiefase, dat wil zeggen de snelheid waarmee het model tokens blijft uitvoeren. Het betekent niet dat de end-to-end responstijd van alle gebruikersverzoeken 85% sneller is.Het vooraf invullen van lange promptwoorden, het ophalen, het aanroepen van tools, wachtrijen en netwerkvertragingen zullen nog steeds van invloed zijn op hoe lang gebruikers daadwerkelijk wachten.
Nadat het model online is, is er nog steeds een gevolgtrekkingsaccount
Dit ding is niet zo levendig als een nieuwe modelrelease, maar het komt dichter in de buurt van de realiteit waarmee AI-bedrijven elke dag worden geconfronteerd:De kosten eindigen niet nadat het model is getraind.
Chatbots, codeassistenten, agenten en op zoekopdrachten gebaseerde producten blijven bij elk gesprek GPU-tijd verbruiken. Als het model langzamer is, zullen gebruikers langer moeten wachten; als inferentie duurder is, zal het voor fabrikanten moeilijker zijn om modellen van hoge kwaliteit open te stellen voor meer scenario's.
De AI-industrie is de afgelopen twee jaar steeds meer gewend geraakt aan het bespreken van trainingskosten: hoeveel GPU’s een bedrijf moet kopen, hoe groot een cluster moet worden gebouwd en hoeveel het gaat kosten om het model van de volgende generatie te trainen. Maar nadat het model daadwerkelijk een product is geworden, zal er steeds een ander soort kosten opduiken: gevolgtrekking.
Trainen is als een groot project, en redeneren is als een energierekening.Zolang gebruikers nog steeds vragen stellen, agenten nog steeds taken uitvoeren en code-assistenten nog steeds patches genereren, zal het model rekenkracht blijven verbruiken.
Grote modeldiensten zullen uiteindelijk terugkeren naar twee indicatoren: snelheid en tokenkosten per eenheid. API-prijspagina's rekenen meestal op basis van invoertokens en uitvoertokens, en bedrijven zullen ook verschillende modellen, caches, routes en contextlengtes intern opsplitsen in kostenposten.
DSpark kan niet direct worden gelijkgesteld met prijsverlaging, maar als hetzelfde GPU-cluster gebruikers in staat stelt sneller antwoorden te krijgen met een vergelijkbare doorvoersnelheid, betekent dit dat dezelfde hardware meer gebruikers kan bedienen, of dezelfde gebruikerservaring kan worden geboden met minder kaarten.
‘Eerst raden, dan testen’
Het idee van speculatieve decodering kan grofweg worden opgevat als "eerst raden, dan testen".
Wanneer een groot model tekst genereert, spuugt het meestal token na token uit. Nadat het vorige token uitkomt, weet het volgende token wat het moet oppakken. Deze methode is stabiel maar langzaam. Door speculatieve decodering kan een lichtere conceptmodule vooraf een kandidaat-token raden, en het grote doelmodel zal in batches worden geverifieerd. De juiste gok wordt direct geaccepteerd en de onjuiste gok wordt gecorrigeerd.
Kleine modellen kunnen geen beslissingen nemen voor grote modellen. Welke tokens uiteindelijk worden geaccepteerd, worden nog steeds geverifieerd door het doelmodel; wanneer het correct wordt geïmplementeerd, verandert het de generatiemethode en verandert het de uitvoerverdeling van het doelmodel niet.De versnelling komt doordat grote modellen kandidaten in batches valideren, in plaats van stapsgewijs.
Wat DSpark heeft veranderd, is de manier waarop een concept kan worden gegenereerd
Het artikel stopt niet bij de uitleg ‘eerst raden, dan testen’. Het richt zich op het genereren van concepten.

De bestaande conceptstrategieën vallen grofweg in twee categorieën uiteen. De autoregressieve drafter is stabieler omdat het latere token het vorige token zal zien, maar naarmate de draft langer wordt, zal de vertraging ook toenemen. De paralleltekenaar is sneller en kan een hele alinea in één keer raden, maar elke positie wordt afzonderlijk geraden. De latere tokens kunnen gemakkelijk worden losgekoppeld van de vorige, en de acceptatiegraad zal waarschijnlijk afnemen naarmate dit later gebeurt.
DSpark kiest voor een compromis.Het sleutelwoord in de titel van het artikel is ‘Semi-autoregressieve generatie’. Het gebruikt eerst een parallelle methode om een kandidaat voor te stellen, en gebruikt vervolgens een lichtgewicht sequentiële laag om de voorwaardelijke relatie van volgende tokens te wijzigen. Hierdoor blijft niet alleen de snelheid van parallelle generatie behouden, maar kunnen volgende kandidaten ook zien wat eerder is geraden.

Een ander belangrijk punt is hoe lang de verificatie duurt.
Hoe meer kandidaatfiches u raadt, hoe minder u bespaart. Als u weet dat de tweede helft waarschijnlijk zal worden afgewezen en deze toch ter verificatie aan een groot model overhandigt, besteedt u GPU-tijd aan een positie met een lage waarde.DSpark zal kijken naar het vertrouwen van de kandidaat en de huidige systeembelasting om de verificatieduur dynamisch te bepalen.Als de GPU leeg is, kun je meerdere tests uitvoeren; wanneer de belasting hoog is, wordt de rekenkracht gereserveerd voor de onderdelen die waarschijnlijker worden geaccepteerd.
Dit is waar de "Confidence-Scheduled" in de titel van het artikel over spreekt.

DSpark staat op bestaande technische routes
DSpark staat na speculatie over de bestaande decoderingsroute en lijkt meer op een openbare referentie nadat DeepSeek deze technische route naar online services heeft gepusht.
SpecInfer heeft al in 2023 kleine modelvoorspellingen, tokenboom en parallelle verificatie in het grote modelservicesysteem geplaatst; Medusa stelde voor om in 2024 meerdere decodeerkoppen aan het model toe te voegen om meerdere opeenvolgende tokens tegelijk te voorspellen; de EAGLE-serie blijft de acceptatiegraad rond diepgangsmodellen en dynamische diepgangsbomen verbeteren. Inferentieframeworks zoals vLLM, SGLang en TensorRT-LLM beschouwen speculatieve decodering al lang als een belangrijk hulpmiddel om de latentie te verminderen.
Het voordeel van DSpark is dat het meerdere productieproblemen samen aanpakt: hoe je concepten kunt genereren, hoe je kandidaten consistent kunt houden, hoe de verificatielengte verandert naarmate de belasting toeneemt en hoeveel snelheid kan worden verbeterd bij echt online verkeer.
Trefwoorden die herhaaldelijk in het artikel voorkomen, zijn ook verschoven van ‘verbetering van modelcapaciteiten’ naar termen aan de servicezijde, zoals generatiesnelheid per gebruiker, aangepaste doorvoer en service level Agreement (SLA).
Dit verklaart ook waarom je niet zomaar het grootste getal kunt kiezen om naar te kijken. Er staan inderdaad gegevens over hoge doorvoer, zoals 661% en 406% in de krant, maar deze zijn afkomstig van strengere snelheidsdoelstellingen per gebruiker: onder die instelling ligt de oude basislijn zelf al dicht bij de grens van de servicemogelijkheden, en het relatieve voordeel van DSpark zal worden vergroot.
Wat de normale voordelen echt kan illustreren is de vorige reeks cijfers: overeenkomende doorvoer, reële verkeersverdeling, en het vergelijkingsobject is MTP-1.
Wat kan DeepSpec reproduceren?
DeepSeek is ook open source DeepSpec. Dit is een codebibliotheek voor het trainen en evalueren van conceptmodellen voor speculatieve decodering. Het omvat gegevensvoorbereiding, training en evaluatieprocessen, en geeft ook relevante controlepunten vrij voor Qwen3, Gemma en andere modellen.
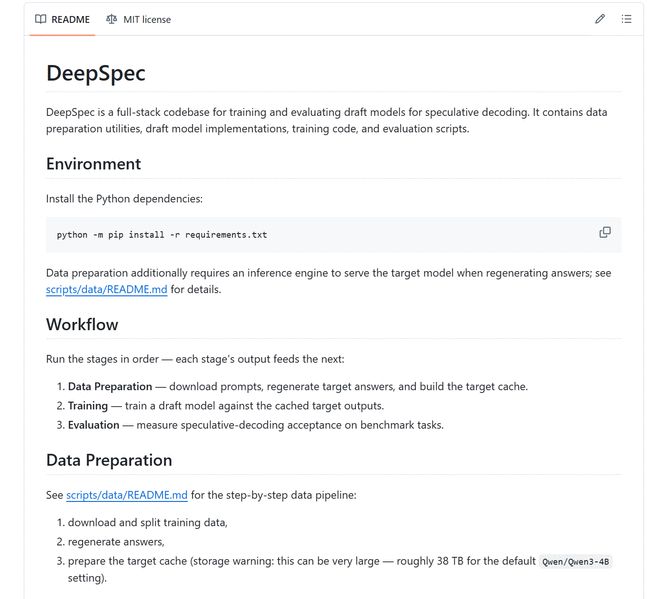
Maar,Open source betekent niet "downloaden en reproduceren".De projectdocumentatie geeft aan dat onder de standaard Qwen3-4B-configuratie de cache van het doelmodel bijna 38 TB kan bedragen; het standaardtrainingsscript gaat uit van 8 GPU's op één knooppunt; Als de papieren resultaten op één lijn moeten worden gebracht, moeten de trainingsinstellingen strikt consistent zijn en is op specifieke gebieden aanvullende verfijning van het conceptmodel vereist.
De buitenwereld kan een deel van de methode verifiëren en DeepSpec ook overbrengen naar andere open source-modellen, maar de reeks snelheidsverbeteringscijfers in de DeepSeek-V4 online service komt nog steeds van DeepSeeks eigen hardwareschaal, verkeersdistributie en productiesysteemplanning.
Open source is de methode, niet de omgeving.
De gemeenschap maakt zich het meest zorgen over terugkerende grenzen
De discussie over
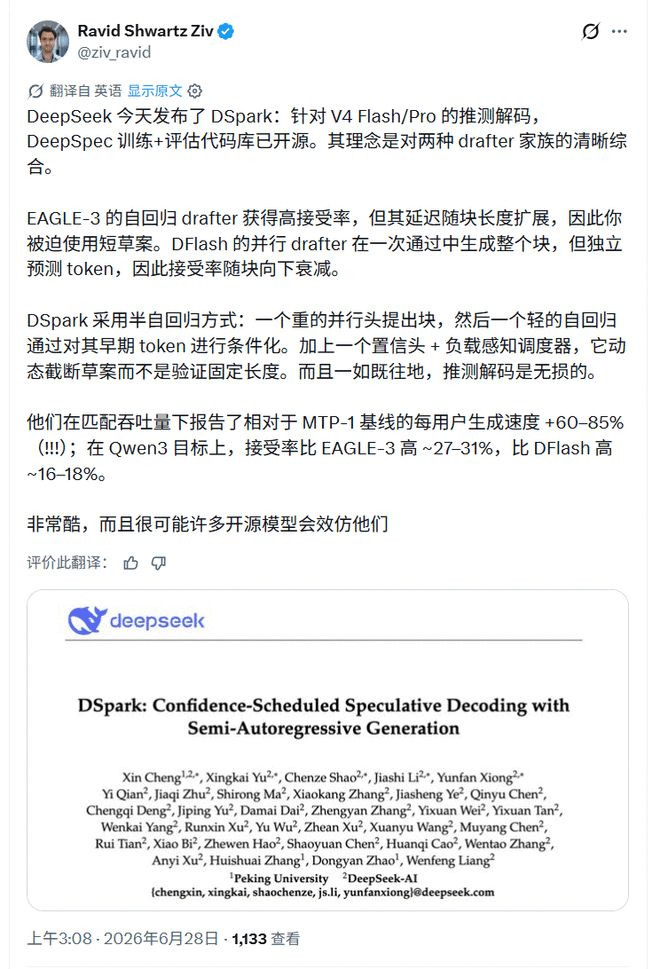
AI-onderzoeker Ravid ShwartzZiv vat DSpark samen als een compromis tussen twee soorten tekenaars: de parallelle tekenaar is snel, maar het acceptatiepercentage neemt af langs het kandidatenblok; de autoregressieve tekenaar is stabiel, maar de vertraging neemt toe met de lengte van het ontwerp. Hij noemde specifiek twee componenten die aan DSpark zijn toegevoegd: de vertrouwensbeoordelingskop en de load-aware planner, en voegde een sleutelgrens toe: "Net als alle speculatieve decodering is deze verliesvrij."
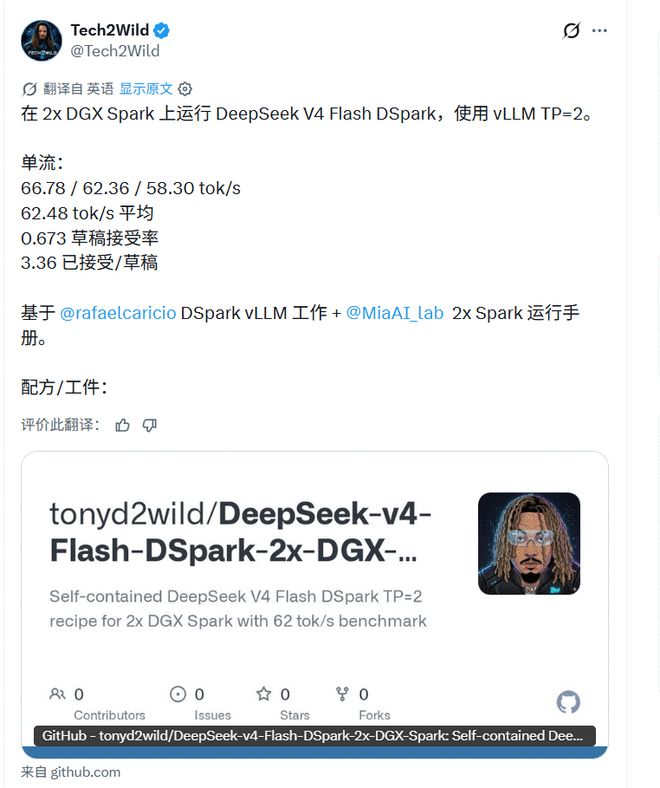
Ingenieurs maken zich meer zorgen over de vraag of het kan werken. vLLM-bijdrager Rafael Caricio zei dat hij de DSpark-modus van DeepSeek-V4-Flash op dual DGX Spark GB10 draaide, en dat de single-stream decodering ongeveer 60 tok/s was, wat ongeveer 1,5 keer zo hoog is als die van MTP-1.
Hij vermeldde ook dat de echte codesessie problemen blootlegde die de synthetische benchmarks niet konden zien: het knelpunt is niet alleen de snelheid van de computerkern, maar het acceptatiepercentage van concepten zal aanzienlijk dalen onder een lange context.
Tech2Wild leverde ook gegevens ter plaatse in een soortgelijke richting, waaruit blijkt dat V4-Flash-DSpark is uitgeprobeerd in een specifieke vLLM-omgeving. Dergelijke resultaten zijn echter sterk afhankelijk van het hardwaremodel, de patchversie van het framework, de contextlengte en de gelijktijdigheidsinstellingen. In een andere omgeving kunnen de resultaten compleet anders zijn.
Er zijn ook mensen die je specifiek op de grenzen wijzen. AcingAI wees erop
Dit herinnert ons eraan dat een deel van het voordeel van DSpark voortkomt uit load-aware planning, en dat het planningseffect uiteraard afhangt van de verkeersschaal en de hardwareconfiguratie van de productieomgeving.
Zelfde kracht, minder rekenkracht
In een rapport van 28 juni keek de South China Morning Post naar DSpark in termen van knelpunten in de gevolgtrekking, chipdruk en wachttijd van gebruikers. Dit perspectief ligt dichter bij de productrealiteit dan "Welk model heeft DeepSeek ook weer uitgebracht?"
AI-bedrijven zullen modelcapaciteiten blijven vergelijken, maar wanneer de capaciteitskloof kleiner wordt, zal wie dezelfde capaciteiten sneller en goedkoper kan leveren ook deel gaan uitmaken van de concurrentie.
Vooral bedrijven als DeepSeek moeten dit duidelijk maken. DeepSeek heeft lage kosten en hoge efficiëntie altijd beschouwd als een belangrijk toegangspunt voor de buitenwereld om dit te begrijpen. Van het modeltrainingsverhaal tot de API-prijs: wat de meeste aandacht trekt, is niet of het een grotere parameterschaal heeft, maar of het dezelfde mogelijkheden goedkoper kan maken.
DSpark zet deze lijn voort: het bewijst niet dat V4 plotseling slimmer is, het bewijst dat V4 minder rekenkracht kan verspillen bij het bedienen van gebruikers.
Als we ons perspectief nog iets verder verbreden, zal inferentie-optimalisatie ook de ecologie van het open source-model beïnvloeden. Het open source-model werd vroeger als ‘goedkoop’ beschouwd, maar als het daadwerkelijk wordt geïmplementeerd, zullen grafisch geheugen, doorvoer, gelijktijdigheid, latentie en complexiteit van bediening en onderhoud allemaal kosten worden.
Als een model open source kan zijn, betekent dit alleen dat iedereen het kan krijgen; Of het een groot aantal gebruikers goedkoop kan bedienen, hangt af van de vraag of de inferentiestapel het bij kan houden.
DeepSpec heeft Qwen3, Gemma en andere controlepunten vrijgegeven, wat aangeeft dat deze kwestie niet stopt bij DeepSeek-V4 zelf. De omvang van de migratie hangt af van de daadwerkelijke voortgang van de gemeenschapsaanpassing, raamwerkondersteuning en hardwarecompatibiliteit; maar afgaande op de huidige publieke informatie heeft DeepSeek deze route uit zijn eigen model gehaald.
De waarde van DSpark ligt hierin.Het voegt een laag van inferentieservicetools toe aan V4 die dichter bij het productiesysteem staat, in plaats van alleen maar een nieuw capaciteitslabel.
Wat de moeite waard is om vervolgens te bekijken, is niet alleen hoe snel DeepSeek kan rennen, maar ook hoeveel mensen deze route kunnen passeren. DeepSpec heeft controlepunten en trainingsprocessen vrijgegeven, en er wordt gespeculeerd dat het decoderen verandert van de technische keuze van een bedrijf naar een gebruikelijke manier van open source-inferentie om de kosten te verlagen.Dat veronderstelt dat andere raamwerken en hardware het bij kunnen houden.