De previewversie van DeepSeek-V4 is eindelijk uitgebracht. Vandaag heeft DeepSeek officieel aangekondigd dat twee modellen, deepseek-v4-pro en deepseek-v4-flash, met een ultralange context van miljoenen woorden, zijn vrijgegeven en open source zijn. Vanaf nu kunt u inloggen op de officiële website of officiële app om met de nieuwste DeepSeek-V4 te praten en de nieuwe ervaring van 1 miljoen (miljoen) ultralang contextgeheugen te verkennen. Tegelijkertijd is de API-service bijgewerkt.

Artikel 丨 "BUG"-kolom Zhou Wenmeng

Volgens de officiële benchmarktest zijn de prestaties van DeepSeek qua contextlengte, kennis, redenering en agentmogelijkheden vergelijkbaar met de beste internationale closed-source modellen en heeft het eersteklas niveau van internationale open-sourcemodellen bereikt. Uit een vergelijking in de kolom 'BUG' bleek dat de V4-versie van DeepSeek, die vorig jaar in zijn eentje voor prijsverlagingen in de binnenlandse grote modellenindustrie zorgde, in termen van API-oproepprijzen opnieuw de 'laagste prijs' in de branche vaststelde.
"Hoewel de belprijs per miljoen tokens van binnenlandse modellen niet veel is gedaald, geven de lange contextlengte en goede prestaties het een zeer concurrentievoordeel!" Sommige insiders uitten hun gevoelens tijdens de communicatie met de "BUG"-kolom. Spijt: "Die grote prijsslager is terug!"
De prestaties zijn vergelijkbaar met het beste closed-sourcemodel, en de kennis en het redeneervermogen zijn leidend
Volgens de officiële introductie van DeepSeek bevat de V4-serie twee versies van het model: DeepSeek-V4-Pro met 1,6T totale parameters, 49B activeringsparameters en 33T pre-trainingsgegevens; DeepSeek-V4-Flash met 284B totale parameters, 13B activeringsparameters en 32T pre-trainingsgegevens; beide ondersteunen native 1 miljoen tokencontexten.
Volgens de door DeepSeek bekendgemaakte benchmarktestgegevens behaalde DeepSeek-V4-Pro-Max in de kennis- en redeneringstests de beste prestaties in de Apex Shortlist- en Codeforces-tests, en overtrof daarmee Claude-Opus-4.6-Max, GPT-5.4-xHigh, Gemin-3.1-Pro-Hight en andere internationale modellen, wat extreem sterke logica- en algoritmemogelijkheden aantoont; in SimpleQA In de Verified-test ligt het iets achter Gemini-3.1-Pro-High, maar vóór Claude en GPT.
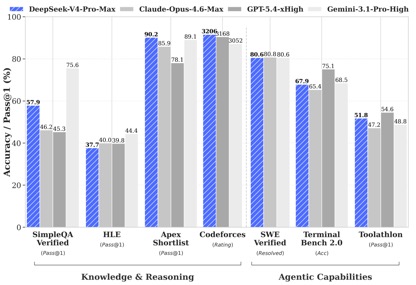
In de Agentic-capaciteitsevaluatie waren de drie modellen V4, Opus-4.6 en Gemin-3.1-pro gelijk op de SWE Verified-taak, en DeepSeek behaalde een niveau dat op de tweede plaats kwam na GPT-5.4-xHigh op de Toolathlon-taak, en op Terminal Bench 2.0 heeft een niveau beter bereikt dan Opus-4.6, wat de voordelen ervan weerspiegelt complexe instructie-uitvoering en scenario's voor het aanroepen van tools.
Momenteel is DeepSeek-V4 het Agentic Coding-model geworden dat door werknemers binnen het bedrijf wordt gebruikt. Volgens evaluatiefeedback is de gebruikservaring beter dan die van Sonnet 4.5, en ligt de leveringskwaliteit dicht bij de niet-denkmodus van Opus 4.6.
Bij de evaluatie van wiskunde, STEM en competitieve codes overtrof DeepSeek-V4-Pro de meeste open source-modellen die publiekelijk zijn geëvalueerd en behaalde resultaten die vergelijkbaar zijn met 's werelds beste closed source-modellen.
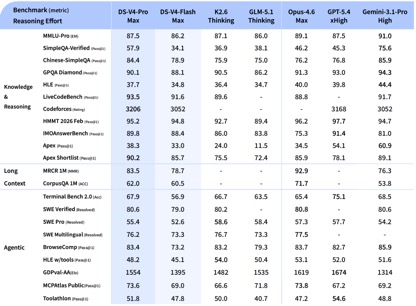
Over het geheel genomen heeft DeepSeek-v4, wat betreft kennisverwerking en redeneermogelijkheden, een algemene voorsprong bereikt op binnenlandse open source-modellen en is het vergelijkbaar met internationale evaluatiemogelijkheden. In termen van Agentic-capaciteiten is de kloof tussen de binnenlandse en internationale eerstelijnscapaciteiten echter niet groter geworden, hoewel de nieuwste DeepSeek-v4 goede verbeteringen heeft aangebracht, en elk van hen ligt voorop.
" Standaard" 1 miljoen context, Prijsslager "is terug"
Vergeleken met de prestatievoordelen die uit verschillende benchmarktests naar voren komen, is het grootste kenmerk van deze V4-release de doorbraak in lange-tekstmogelijkheden en de verdere verlaging van de prijzen voor API-aanroepen.
Dankzij het nieuwe aandachtsmechanisme dat is ontwikkeld door DeepSeek-V4, bereikt V4 toonaangevende lange-contextmogelijkheden door de tokendimensie te comprimeren en te combineren met DSA-sparse aandacht (DeepSeek Sparse Attention). Vergeleken met traditionele methoden vermindert het de vereisten voor computer- en videogeheugen aanzienlijk, waardoor 1M (een miljoen) context de standaard wordt voor alle officiële DeepSeek-services.
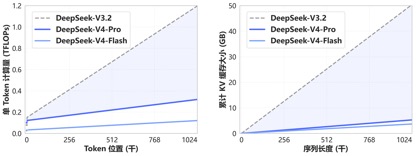
Een jaar geleden waren 1 miljoen contexten de exclusieve troef van Gemini. Zelfs in de meeste recent uitgebrachte reguliere binnenlandse open source-modellen lag de lengte van de modelcontexten meestal in het bereik van 128K-200K. DeepSeek transformeerde de miljoen contexten rechtstreeks van "high-end closed source-functies" naar open source-standaardconfiguraties.
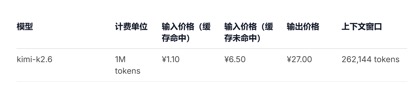
In termen van API-prijsoproepen, vergeleken met de huidige GLM-5.1 invoereenheidsprijs van 1,3 yuan-2 yuan/miljoen tokens (cachehit) en Kimi-K2.6 1,1 yuan/miljoen tokens (cachehit), DeepSeek-v4 -Voor de pro- en flash-versies zijn de invoereenheidsprijzen respectievelijk 1 yuan/miljoen tokens en 0,2 yuan/miljoen tokens. Hoewel de prijzen niet veel zijn gedaald, zijn ze allebei de laagste en is de contextlengte meerdere keren uitgebreid.
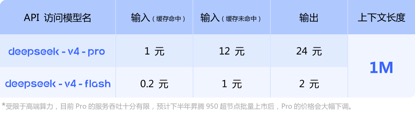
(API-aanroepprijs voor DeepSeek-v4-serie model)
[GT20GT ]
(API-aanroepprijs voor Kimi-k2.6-model)
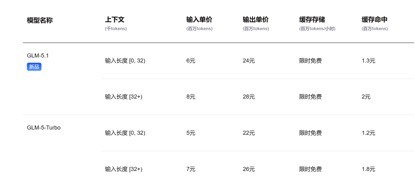
(GLM-5.1-model API-aanroepprijs)
"De prestatiedoorbraak die de release van DeepSeek-v4 met zich meebrengt, heeft minder impact dan de release van DeepSeek-R1. De prestaties bevinden zich nog steeds in het eerste echelon, maar de voorsprong is niet volledig uitgebreid." Volgens insiders uit de sector gaat "de release van het V4-model meer over de verbetering van de mogelijkheden voor lange tekst en de verdere prijsverlaging."
[ GT1GT] Deze persoon klaagde: "Na de vorige release van de DeepSeek-V3- en R1-modellen hebben de prestatievoordelen van de onderliggende technologische innovatie rechtstreeks de collectieve prijsverlaging van de hele binnenlandse grote modellenindustrie bevorderd. Hoewel de belprijs per miljoen tokens van de V4-versie niet veel is gedaald vergeleken met binnenlandse collega's, is deze nog steeds competitief. De prijsslager voor grote modellen is terug!""De rekenkracht van Huawei zal in de tweede helft van het jaar in batches worden toegevoegd en de Pro-prijs zal aanzienlijk worden verlaagd."
Het is vermeldenswaard dat onderaan de API-prijsinformatie vrijgegeven door DeepSeek-v4 de functionaris specifiek opmerkte: "Beperkt door high-end computerkracht, is de huidige servicedoorvoer van Pro zeer beperkt, en er wordt verwacht dat er in de tweede helft van het jaar 950 supernodes zullen stijgen. Na de massale lancering zal de prijs van Pro aanzienlijk worden verlaagd. "

Dit betekent dat de modellen uit de v4-serie die dit keer zijn uitgebracht, zijn aangepast voor Huawei's Ascend 950 supernode. Zolang de Ascend 950 wordt gelanceerd, kan het merendeel van de gebruikers DeepSeek-v4 gebruiken op basis van binnenlandse rekenkracht die vergelijkbaar is met de beste internationale closed-source modellen.
In het officiële open source technische document vermeldde DeepSeek dit ook en zei dat v4 is geïmplementeerd op NVIDIA GPU en HUAWEI Ascend. Het fijnmazige EP-schema (expert parallellisme) is geverifieerd op het NPU-platform. Vergeleken met de krachtige niet-fusiebasislijn kan het een versnellingseffect van 1,50-1,73 maal bereiken op algemene redeneringstaken, en een versnellingseffect van 1,96 maal in vertragingsgevoelige scenario's (zoals RL-aftrek en snelle proxydiensten).

Na de release van V4 kondigde Huawei Ascend ook aan dat "het volledige assortiment supernode-producten modellen uit de DeepSeek V4-serie ondersteunt." Er wordt gemeld dat Ascend 950 de aandachtsberekening en de geheugentoegangsoverhead vermindert door kernel- en multi-stream parallelle technologie te integreren, de inferentieprestaties aanzienlijk te verbeteren en meerdere kwantiseringsalgoritmen te combineren om een hoge doorvoer en lage latentie te bereiken. DeepSeek V4-modelinferentie-implementatie.
Eerder deze maand accepteerde NVIDIA-oprichter Huang Jensen Dwarkesh. In een exclusief interview zei Patel: "Als DeepSeek eerst op het Huawei-platform wordt uitgebracht, zal dat rampzalig zijn voor ons land (de Verenigde Staten)." Volgens Huang Renxun is DeepSeek weliswaar een open source-model en kan het ook op NVIDIA-producten worden gebruikt, maar als DeepSeek specifiek is geoptimaliseerd voor de rekenkracht van Huawei, zal NVIDIA in het nadeel zijn vanwege beperkingen zoals beperkingen op de aankoop van geavanceerde rekenkracht.
Nu lijkt het erop dat, hoewel DeepSeek ook de EP-oplossing voor de rekenkracht van Nvidia heeft geverifieerd, waar Huang Renxun zich zorgen over maakte, nog steeds is gebeurd. In de ogen van insiders uit de industrie is "V4 een product dat wordt geforceerd door rekenkracht. Het komende jaar zullen grote binnenlandse modellen geleidelijk volwassener worden als ze op binnenlandse kaarten draaien."
Multimodale mogelijkheden zijn nog niet verschenen
Helaas, hoewel DeepSeek V4 is uitgebracht, is deze versie nog steeds een puur tekstmodel zonder veel multimodale mogelijkheden zoals Vincent-foto's en Vincent-video's. Hierdoor kunnen gewone gebruikers een model ook snel ervaren en evalueren, wat een hoop moeilijkheid met zich meebrengt.

Naarmate de mogelijkheden van grote taalmodellen blijven verbeteren en het aantal hallucinaties geleidelijk afneemt, is het immers moeilijk voor conventionele en enkelvoudige kennisvragen en antwoorden om de uitgebreide mogelijkheden van een model objectief weer te geven. Als de meeste gebruikers de mogelijkheden van het V4-model intuïtief willen ervaren, moeten ze het downloaden en een tijdje persoonlijk gebruiken.
Tegelijk met de release van de V4-modellenreeks heeft DeepSeek onlangs ook onthuld dat het van plan is 50 miljard yuan op te halen. Mensen die dicht bij DeepSeek stonden, onthulden dat de voorfinancieringswaarde van DeepSeek 300 miljard yuan bedraagt, ongeveer 44 miljard dollar. Momenteel onderhandelen Tencent Holdings en Alibaba Group over investeringen in DeepSeek. DeepSeek heeft echter niet rechtstreeks gereageerd op vragen van de media over financieringsgerelateerde zaken.
Misschien is het voor DeepSeek-oprichter Liang Wenfeng een verstandige zet om de release van V4 te gebruiken om tijdige financiering te verkrijgen om de kracht ervan te versterken wanneer de groei van de "intelligentie" van mondiale grote modellen vertraagt, de concurrentie om talenten uit de industrie toeneemt en de multimodale en agentische trends in de industrie steeds meer worden benadrukt.