Deze keer stond Ultraman niet op en zei: "De eerste keer dat ik het meemaakte, was ik zo bang dat ik flauwviel en instortte. Op dat moment was het alsof ik een atoombom zag ontploffen." In plaats daarvan huurde hij een groep vervangers (vroege testgebruikers) in. Onder hen was een Nvidia-ingenieur die na vroege tests kortstondig de toegang tot GPT-5.5 verloor en dit zei:

Het verliezen van GPT-5.5 is als een amputatie.
Laten we praten, laten we problemen veroorzaken.
Deze samenwerking tussen OpenAI en NVIDIA is ongekend.
Ten eerste zijn GPT-5.5 en NVIDIA GB200 en GB300 NVL72-systemen gezamenlijk ontworpen. Van training tot implementatie: de relatie tussen model en hardware is sinds de geboorte bidirectioneel geweest.
Ten tweede plaatste Ultraman, om Codex bij het hele NVIDIA-bedrijf te promoten, ook een e-mail met Lao Huang.
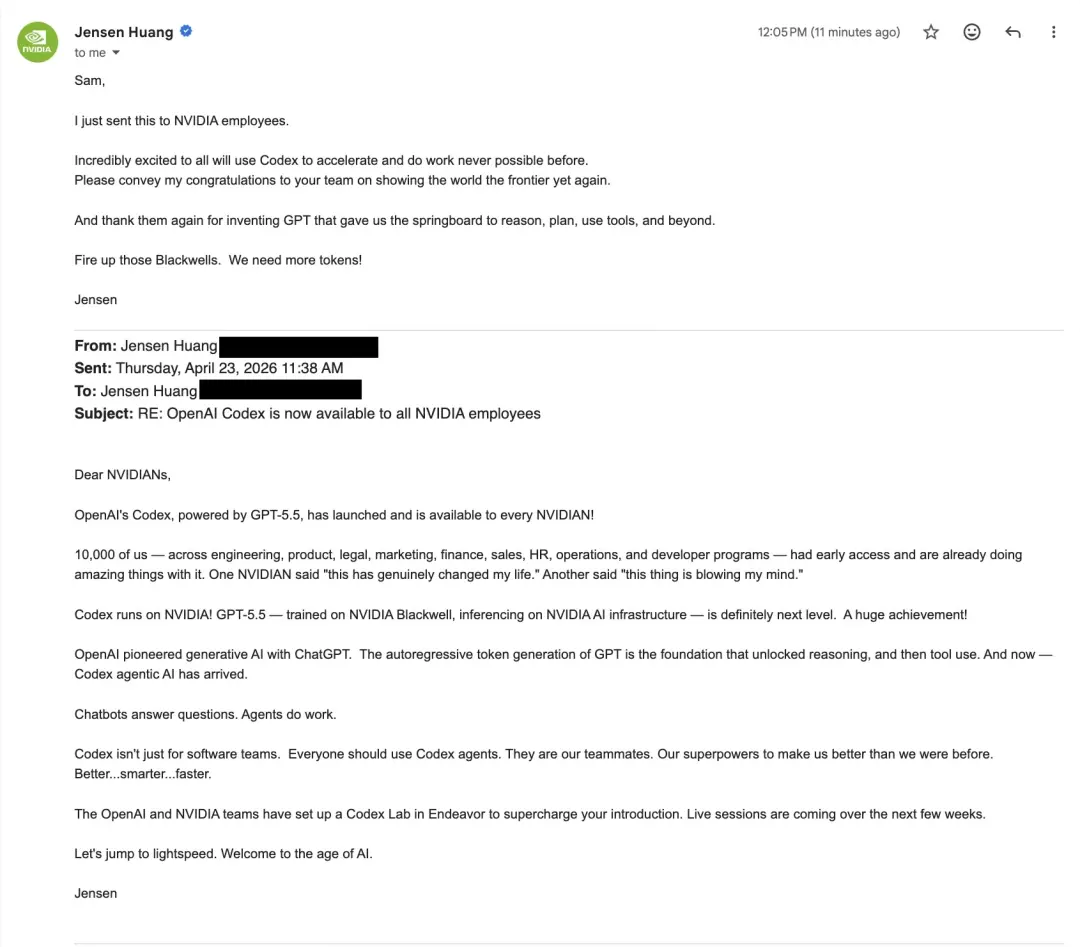
Laten we eerst eens kijken naar de resultaten van de samenwerking.
Vergeleken met de vorige versie GPT5.4 heeft het nieuwe model het voortouw genomen op alle drie de gebieden: code, kenniswerk en wetenschappelijk onderzoek.
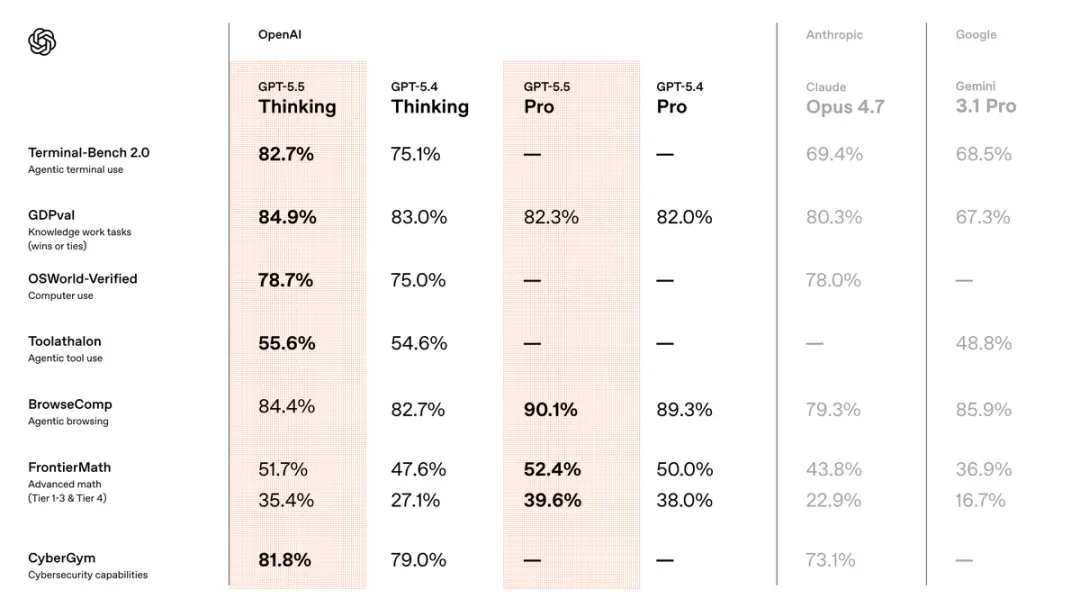
Uitgebreide testresultaten van de Artificial Analysis Intelligence Index, er zijn twee manieren om te interpreteren:
GPT-5.5 behaalt dezelfde score en verbruikt minder tokens dan Claude Opus 4.7 en andere modellen.
Of als je hetzelfde token gebruikt, kan GPT-5.5 meer taken voltooien.
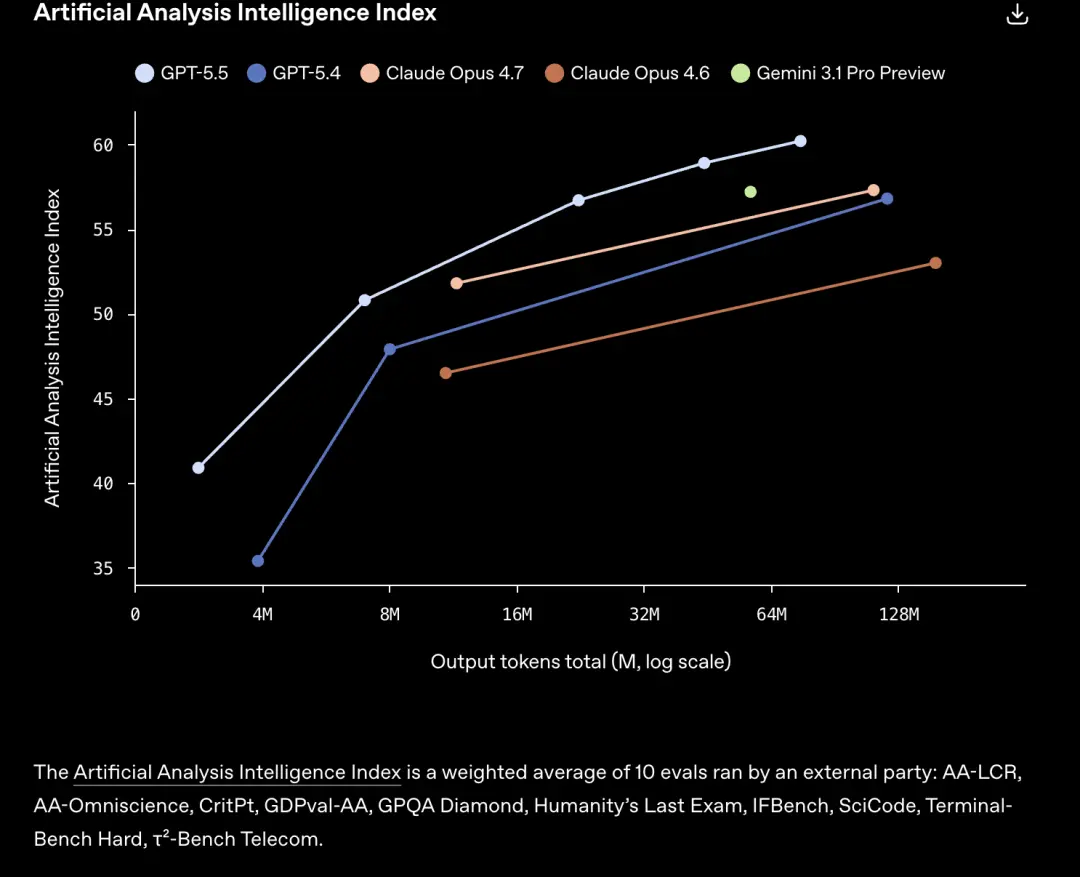
Maar het meest verrassende is niet de lopende score.
In het verleden werd elke modelupgrade, "sterker" en "langzamer", bijna in één pakket verkocht.
Dit is de prijs van de schaalwet, een groter model, meer parameters en een langere denktijd. Wanneer gebruikers voor intelligentie betalen, betalen ze ook voor vertraging.
GPT-5.5 overtreedt deze ijzeren wet.
In een echte productieomgeving is de token-voor-token latentie gelijk aan die van GPT-5.4, en zijn er minder tokens nodig om dezelfde taak te voltooien dan GPT5.4.
is efficiënter en krachtiger.
(maar de prijs is verdubbeld)

Op het moment van schrijven kan de nieuwste versie van de Codex-update al gebruik maken van GPT-5.5.
Het contextvenster is ook geüpgraded naar 400K
[GT32 GT]
Programmeerhacks
Programmeren is het gebied waarop GPT-5.5 het meest is verbeterd.
Als je het model van de vorige generatie gebruikt, moet je de taken nog steeds zorgvuldig opsplitsen, stap voor stap bekijken en op elk moment klaar staan om afwijkingen te corrigeren.
GPT-5.5 is anders. Je gooit de eisen omver en het demonteert, voert uit en controleert zichzelf. Je hoeft alleen maar naar de resultaten te kijken.
OpenAI demonstreerde een 3D-actiespel gegenereerd door GPT-5.5 onder Codex, dat rechtstreeks op de webpagina draait.
omvat het gebruik van TypeScript/Three.js om het vechtsysteem, vijandelijke ontmoetingen, HUD-feedback en door GPT gegenereerde omgevingstexturen te implementeren.
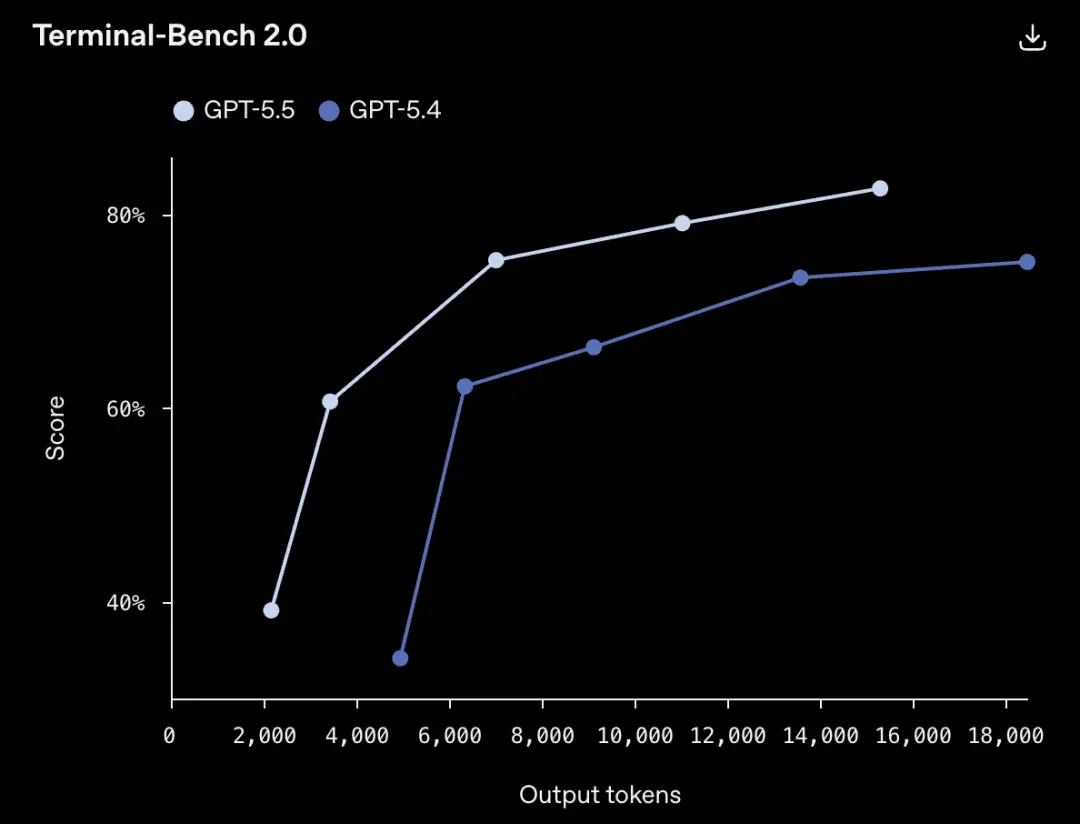
Terminal-Bench 2.0, een hardcore test die complexe opdrachtregelworkflows meet, kreeg GPT-5.5 82,7%.
De GPT-5.4 van de vorige versie was 75,1% en de huidige sterkste concurrent, Claude Opus 4.7, was 69,4%.
Het is begrijpelijk dat bijna een derde van de modellen van de vorige generatie bij deze moeilijkheidsgraad vast zou lopen, maar nu is dit aandeel gedaald tot minder dan een kwart.
Geef vervolgens je mond een vervanger:
Vroege tester Dan Shipper deed een experiment. Hij is een startup-CEO en een actieve AI-productontwikkelaar.
Er zat een bug in zijn app nadat deze was gelanceerd, dus huurde hij een topingenieur in om deze te reconstrueren. De engineers hebben hard gewerkt en uiteindelijk met een oplossing gekomen.
Vervolgens draait de verzender de klok terug: gooi de foutcode naar het model en kijk of het zelfstandig dezelfde beslissing kan nemen als de ingenieur.
GPT-5.4 kan het niet. GPT-5.5 deed het.
Shipper zei dat dit de eerste keer was dat hij echte "conceptuele helderheid" in een programmeermodel ervoer.
beantwoordt de oproep niet, maar begrijpt het probleem en zoekt uit hoe het kan worden opgelost.

Steeds meer ervaren ingenieurs melden hetzelfde: GPT-5.5 is aanzienlijk sterker dan GPT-5.4 en Claude Opus 4.7 wat betreft redenering en autonomie.
Het detecteert problemen vooraf en anticipeert op test- en beoordelingsbehoeften zonder expliciete aanwijzingen.

Programmeren is nog maar het begin. Dezelfde capaciteitssprong breidt zich uit naar zowel kenniswerk als wetenschappelijk onderzoek.
Naast programmeren
Wat GPT-5.5 doet in Codex is veel meer dan alleen het schrijven van programma's. Genereer documenten, organiseer formulieren en maak PPT.
OpenAI heeft vaak benadrukt dat het beter begrijpt wat je wilt dan de vorige generatie.
Wat belangrijker is, is dat zijn eigen tools zal gebruiken om te controleren of de uitvoer correct is. Jij geeft mij een vaag idee en het kan je helpen de rest in te vullen.
Er zijn hier zeer interessante gegevens. Ruim 85% van de medewerkers van OpenAI werkt wekelijks aan Codex. (Wat is er aan de hand met de andere 15%?)
Laten we eerst naar de evaluatieresultaten kijken.
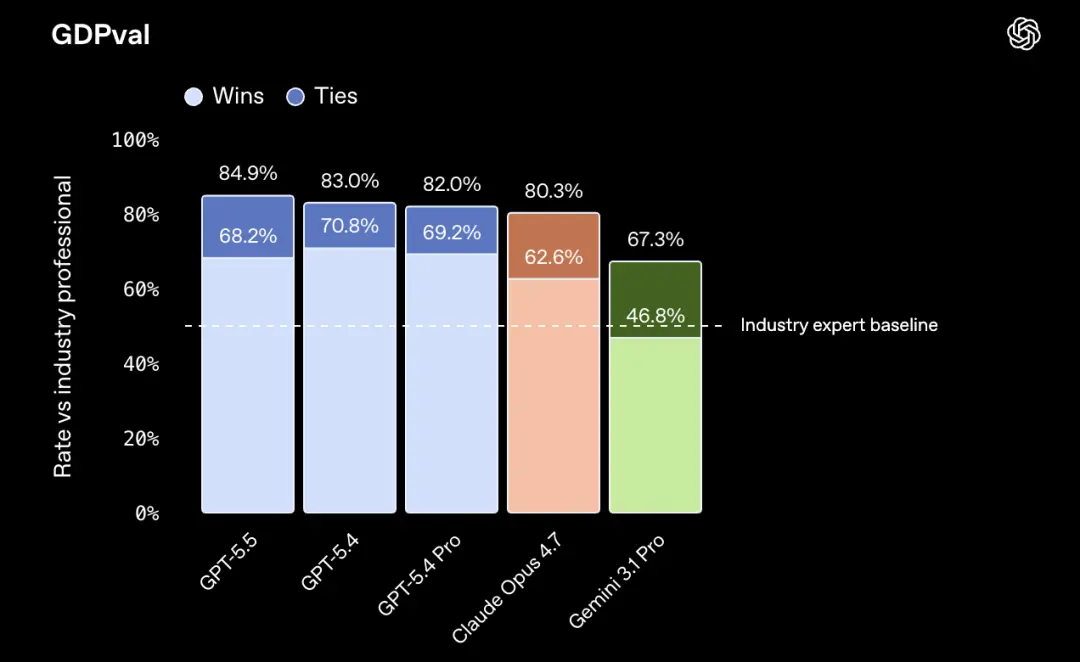
Op de kenniswerkbenchmark GDPval behaalde GPT-5.5 84,9%, 4,6 procentpunten hoger dan Claude Opus 4.7.
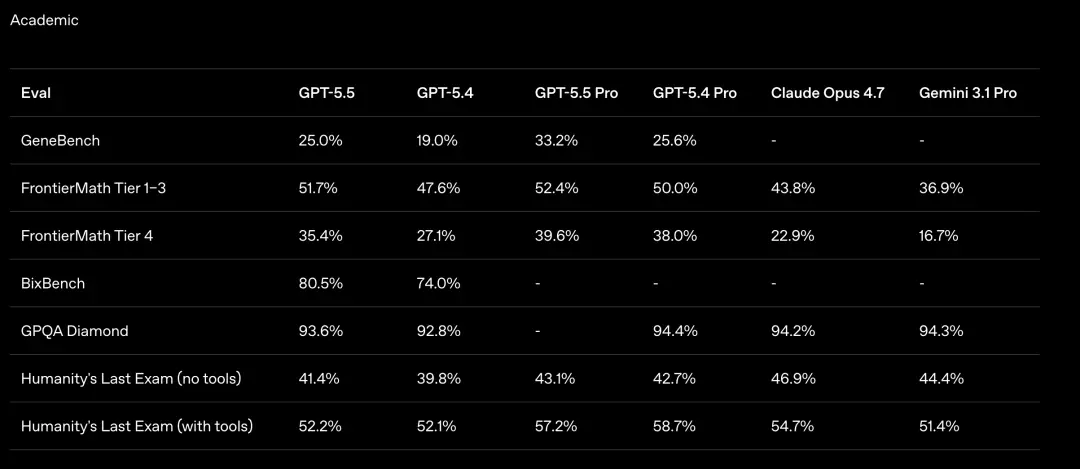
FrontierMath Tier 4, Een van de moeilijkste wiskundebenchmarks van dit moment; de vragen komen uit ongepubliceerde artikelen en openstaande problemen van toponderzoekers.
GPT-5.5 Pro scoorde 39,6% in deze test. Claude Opus 4.7 bedraagt 22,9%, het verschil is bijna het dubbele.
Wat echt interessant is, is hoe wetenschappers het gebruiken.
Bartosz Naskręcki is assistent-professor wiskunde aan de Adam Mickiewicz Universiteit in Polen. Hij schreef een zin aan de Codex en elf minuten later draaide er een visualisatietoepassing voor algebraïsche meetkunde.
Deze applicatie kan de snijlijn van twee kwadratische oppervlakken tekenen, rood gemarkeerd, en kan ook de stelling van Riemann-Roch gebruiken om de snijlijn om te zetten in de standaardvorm van de Weierstrass-curve. Later breidde hij het uit met stabielere mogelijkheden voor singulariteitsvisualisatie.
In één zin, 11 minuten. Vroeger kostte het opzetten van het projectkader alleen al een halve dag.

Derya Unutmaz is hoogleraar immunologie aan het Jackson Laboratory for Genomic Medicine. Hij gebruikte GPT-5.5 Pro om een dataset voor genexpressie te analyseren: 62 monsters, bijna 28.000 genen. Uiteindelijk is er een compleet onderzoeksrapport verschenen.
Het zou het team enkele maanden hebben gekost, zei hij.
OpenAI’s positionering van GPT-5.5 in wetenschappelijk onderzoek kan nauwkeurig in één zin worden samengevat. Het is niet langer een eenmalige antwoordmachine, maar meer een ‘onderzoekspartner’.
Vroege testers gebruiken het voor meer dan alleen het opzoeken van informatie. Meerdere rondes waarin het artikel werd gecorrigeerd, de mazen in de argumentatie één voor één werden geïdentificeerd en nieuwe analyseplannen werden voorgesteld. Het onthoudt uw volledige onderzoekscontext en elk gesprek bouwt voort op het vorige.
GPT-5.5 heeft iets groots gedaan op het gebied van de wiskunde.
Ramsey-getal, een van de kernproblemen in de combinatorische wiskunde.
In termen van de leek onderzoekt het: hoe groot moet een netwerk zijn om ervoor te zorgen dat een bepaalde orde onvermijdelijk zal verschijnen?
Drie van de zes mensen moeten elkaar bijvoorbeeld kennen, of drie mensen mogen elkaar niet kennen. Dit is de eenvoudigste stelling van Ramsey.
Het is al tientallen jaren een harde noot op het gebied van de wiskunde, en de asymptotische eigenschappen van niet-diagonale Ramsey-getallen zijn al lange tijd onopgelost.
GPT-5.5 vindt een nieuw proefpad. In plaats van een bekende methode te reproduceren, ontdekten we een nieuw pad. Vervolgens werd dit bewijs bevestigd door Lean, een van de meest rigoureuze formele verificatie-instrumenten in de wiskunde.

Een AI die originele bijdragen heeft geleverd, geverifieerd door formele hulpmiddelen op het kerngebied van de zuivere wiskunde.
Een jaar geleden zou dit ondenkbaar zijn geweest.
Het geheim van sterker maar niet sneller zijn
Hoe bereik je "sterker maar niet sneller"?
Het antwoord is niet het optimaliseren van een bepaalde link. OpenAI gooide het hele redeneersysteem omver en begon opnieuw.
Zoals eerder vermeld, zijn GPT-5.5- en NVIDIA GB200- en GB300 NVL72-systemen gezamenlijk ontworpen. Als gevolg hiervan is het intelligentieniveau, onder dezelfde vertraging, aanzienlijk gestegen.
Maar er is nog een ander verhaal.
Het door GPT-5.5 aangestuurde Codex-systeem analyseerde enkele weken aan productieverkeersgegevens en schreef vervolgens een heuristisch algoritme voor taakverdeling.
Voorheen werden verzoeken opgesplitst in een vast aantal delen en ter verwerking naar accelerators gedistribueerd. Een vaste chunkingstrategie is echter niet altijd optimaal onder verschillende verkeerspatronen. Soms zijn de blokken te grof verdeeld, soms te dun, en is de benuttingsgraad van de hulpbronnen hoog en laag.
Codex heeft een paar weken aan echte verkeersgegevens bekeken en een reeks adaptieve partitie-algoritmen geschreven. Pas de blokkeerstrategie dynamisch aan op basis van werkelijke verkeerspatronen.
De snelheid voor het genereren van tokens is met meer dan 20% verhoogd.
Het model optimaliseert de infrastructuur om zichzelf te laten draaien, en de AI zorgt ervoor dat zichzelf sneller werkt.
Bij de algehele reconstructie van het gevolgtrekkingssysteem, gekoppeld aan de deelname van het model aan zijn eigen optimalisatie, overlappen twee dingen elkaar om zulke resultaten te verkrijgen.

OpenAI zegt dat dit "een stap is in de richting van een nieuwe manier om dingen gedaan te krijgen met computers."
Maar nu het model is begonnen met het optimaliseren van de infrastructuur voor zijn eigen werking -
Hoe ver is het gegaan?
Nog één ding
Met GPT-5.5 verwacht OpenAI dat de gegevens over modelreleases in de toekomst zullen versnellen.
We zien behoorlijk aanzienlijke vooruitgang op de korte termijn en uiterst aanzienlijke vooruitgang op de middellange termijn.
Ik denk dat de vooruitgang de afgelopen jaren verrassend langzaam is gegaan.
Het was hoofdwetenschapper Jakub Pachocki die dit zei tijdens een telefonische vergadering met verslaggevers.