AMD promoot een visie op kunstmatige intelligentie die niet afhankelijk is van de cloud. Het onlangs uitgebrachte OpenClaw-framework, gecombineerd met twee sets hardwarereferentieconfiguraties RyzenClaw en RadeonClaw, is ontworpen om ontwikkelaars en early adopters in staat te stellen grote taalmodellen en multi-agent-workflows op lokale pc's uit te voeren. Deze stap maakt deel uit van AMD's grotere 'Agent Computer'-plan, dat gelooft dat de toekomst van AI niet beperkt moet blijven tot afgelegen datacenters, maar gebruikers controle moet geven over hun eigen data- en computeromgeving, lokale AI-assistenten lange tijd aan de praat moet houden, de netwerkafhankelijkheid en abonnementslasten moet verminderen en privacyproblemen moet verlichten.

Vanuit technisch perspectief draait OpenClaw momenteel op het Windows-platform via WSL2 (Windows Subsystem for Linux 2), en LM Studio wordt gebruikt met de llama.cpp-backend om lokale inferentietaken uit te voeren. In deze omgeving kunnen gebruikers modellen, waaronder Qwen 3.5 35B A3B, rechtstreeks op de machine uitvoeren. Het systeem ondersteunt ook een ingebed geheugenframework genaamd Memory.md voor het lokaal opslaan van contextuele informatie zonder afhankelijk te zijn van cloudsynchronisatie. AMD positioneert de officiële tutorial als een relatief gestroomlijnd configuratiepad om ontwikkelaars in staat te stellen een complete OpenClaw-omgeving op Windows te bouwen en de AI-agentarchitectuur te testen, maar het document geeft geen duidelijke geschatte configuratietijd.

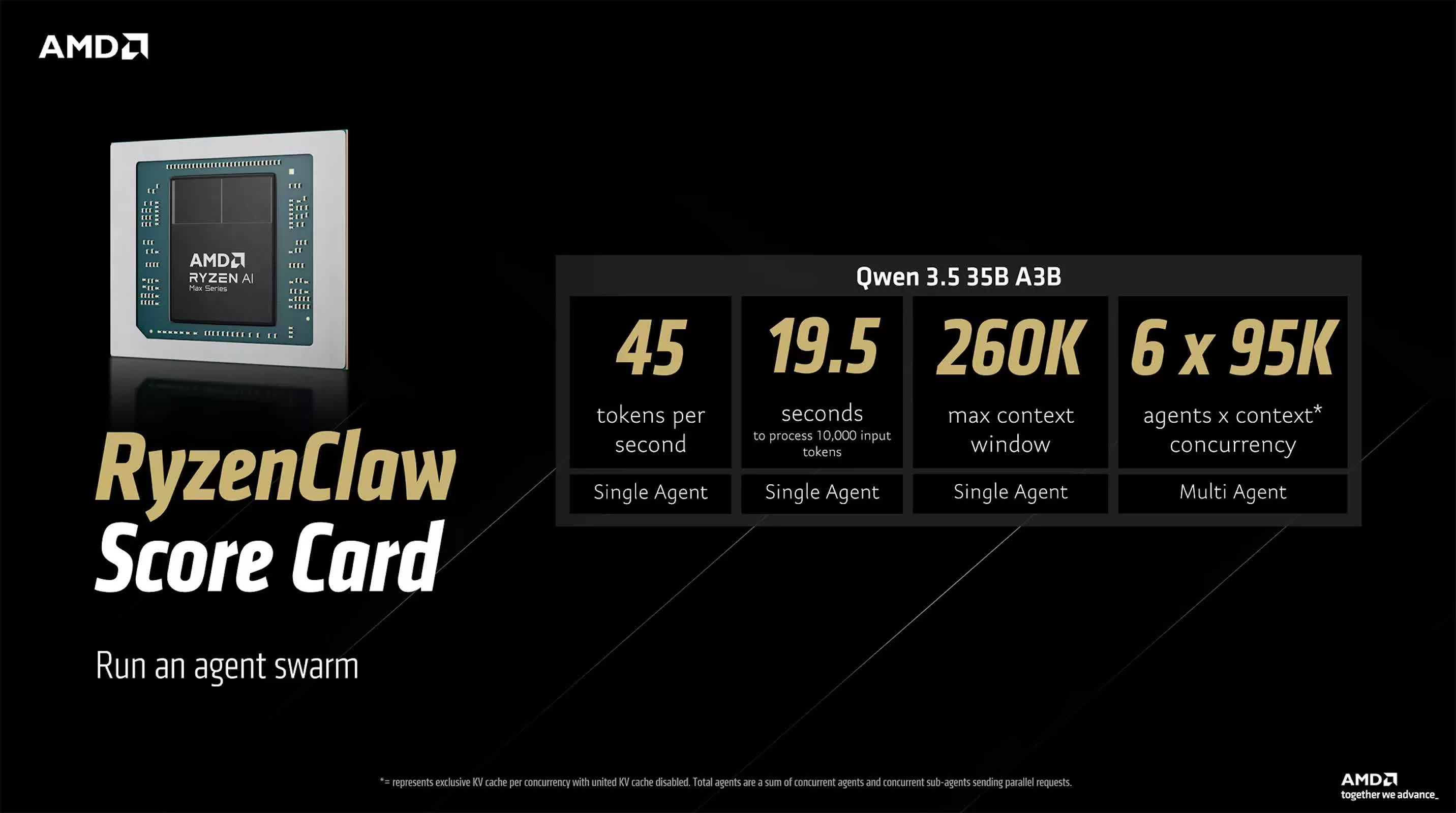
De twee door AMD voorgestelde OpenClaw-referenties vertegenwoordigen verschillende routes naar ‘high-performance native AI’. De RyzenClaw-oplossing is gebouwd rond de Ryzen AI Max+ processor en is uitgerust met 128 GB verenigd geheugen, waarvan AMD aanbeveelt om ongeveer 96 GB toe te wijzen als variabel videogeheugen om de inferentie-efficiëntie van grote modellen te garanderen. Onder deze configuratie genereert Qwen 3.5 35B A3B ongeveer 45 tokens per seconde, heeft het ongeveer 19,5 seconden nodig om een invoer van 10.000 tokens te verwerken, ondersteunt het een contextvenster van ongeveer 260.000 tokens en kan het worden gebruikt in multi-agent workflows of "agent cluster" experimentele omgevingen. AMD zegt dat het platform maximaal zes lokale AI-agenten tegelijk kan gebruiken, wat typerend is voor systemen die niet op datacenterniveau zijn.

Een andere RadeonClaw-configuratie verlegt de focus van de rekenkracht naar de onafhankelijke GPU: Radeon AI PRO R9700. Deze grafische kaart van werkstationklasse biedt 32 GB speciaal grafisch geheugen, waardoor de inferentiedoorvoer aanzienlijk wordt verhoogd. Onder hetzelfde model kan de generatiesnelheid worden verhoogd tot ongeveer 120 tokens per seconde, waardoor de tijd voor het verwerken van een invoer van 10.000 tokens wordt verkort tot ongeveer 4,4 seconden. Deze prestatiewinst gaat echter gepaard met bepaalde afwegingen: het maximale contextvenster wordt teruggebracht tot ongeveer 190.000 tokens, en het aantal gelijktijdige agenten wordt teruggebracht tot 2. Deze verschillen benadrukken de poging van AMD om verschillende afstemmingspaden te bieden waarmee ontwikkelaars een grotere contextdiepte en snellere gevolgtrekking kunnen inruilen op basis van hun behoeften.
Qua positionering zijn noch RyzenClaw noch RadeonClaw een instapconfiguratie voor gewone consumenten. Als we RyzenClaw als voorbeeld nemen: een desktopcomputer gebaseerd op de Ryzen AI Max+ 395-chip en uitgerust met 128 GB geheugen (zoals het Framework Desktop-abonnement) begint bij ongeveer $ 2.700. Als je de RadeonClaw-route kiest, moet je ook de Radeon AI PRO R9700 grafische kaart aanschaffen, die alleen al een adviesprijs heeft van ongeveer $ 1.299. AMD geeft momenteel toe dat de belangrijkste doelgroepen van OpenClaw ingenieurs en early adopters zijn die experimenteren met lokale AI-agenten, in plaats van reguliere pc-gebruikers.

Toch gaat de boodschap van OpenClaw verder dan de specifieke hardware zelf. AMD gokt op een trend waarin ontwikkelaars autonomie en privacy zullen waarderen boven uitbreiding op cloudschaal, in de hoop een brug te slaan tussen personal computing en gedistribueerde AI via lokale agenten die op consumentenchips draaien. Als dit idee door het ecosysteem wordt erkend, wordt verwacht dat AMD een unieke positie zal innemen in het snel evoluerende AI-landschap, waardoor sommige high-end desktops en werkstations geleidelijk aan AI-verwerkingsmogelijkheden dicht bij datacentra kunnen krijgen, terwijl een gevoel van controle en flexibiliteit aan de gebruikerskant behouden blijft.