Vanochtend vroeg lanceerde Anthropic het krachtigste Sonnet-model in de geschiedenis——Claude Sonnet 4.6Hier komt het, het nieuwe model is erProgrammeren, computergebruik, redeneren in lange context, agentplanning, kenniswerk en ontwerpwerkalomvattende evolutie.
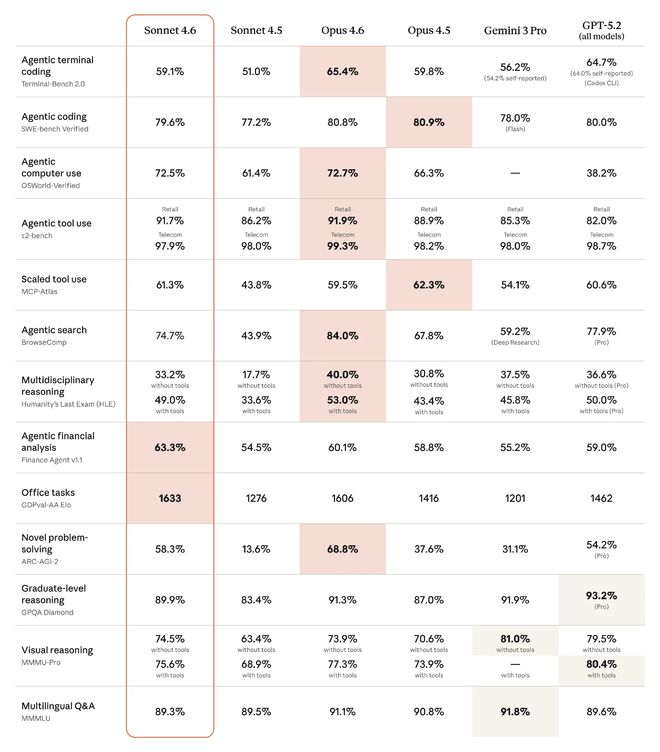
Afgaande op de benchmarktestresultaten gepubliceerd door Anthropic, Claude Sonnet 4.6'sHet intelligentieniveau ligt dicht bij het Opus-niveau, wat betreft financiële analyses van agenten, kantoortaken en visueel redenerenIn verschillende evaluatieszelfs meer danNet uitgebracht op 6 februariOpus 4.6, maar dan betaalbaarder. In de modellenreeks van Claude wordt het kleinste model gewoonlijk Haiku genoemd, het middelgrote model Sonnet en het grootste en intelligentste model Opus.
Na de release van Sonnet 4.6 jammerden de Amerikaanse softwareaandelen. Vanaf de afsluiting op dinsdag Eastern Time daalde Intuit met meer dan 5%, Oracle en Applovin daalden met meer dan 3%, Salesforce, Atlassian, Palo Alto Networks en Autodesk daalden met meer dan 2%, en Adobe en ServiceNow daalden met meer dan 1%.
Een ontwikkelaar maakte zijn proefervaring bekend op het sociale platformDe prijs is bijna de helft goedkoper.

▲Ervaar voorbeelden van Claude Sonnet 4.6 op sociaal platform X
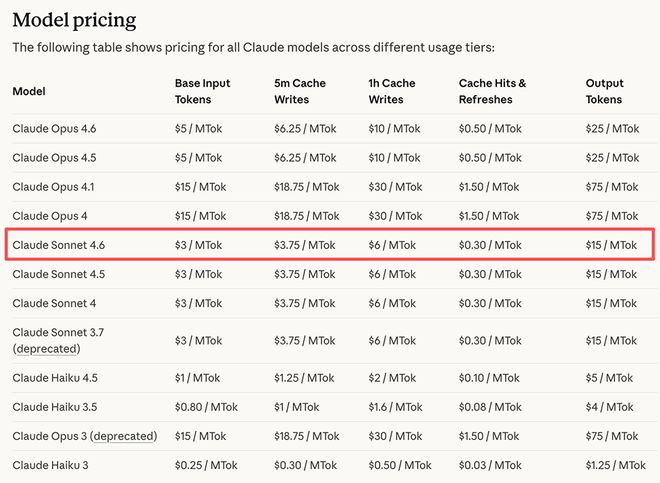
Sonnet 4.6 bèta heeftContextvenster van 1 miljoen tokens. Voor gratis en Pro-abonnees is Claude Sonnet 4.6 het standaardmodel geworden voor claude.ai en Claude Cowork, en ondersteunt nu het maken van bestanden, connectoren, expertise en inhoudscompressie. De prijs van dit model komt overeen met Sonnet 4.5, met een invoerprijs per miljoen tokens van$3(ongeveer 21 RMB), de afzetprijs is$ 15(ongeveer RMB 104).
AWS maakte onmiddellijk bekend dat Sonnet 4.6 is uitgebracht op Amazon Bedrock. AWS zegt dat dit antropisch isHet krachtigste computergebruiksmodelVoor bedrijven die hun AI-workflows opschalen betekent dit een hogere ROI zonder dat dit ten koste gaat van de kwaliteit.

Dit is ook de eerste keer dat Anthropic een nieuw model heeft onthuld sinds het een eenhoorn van een biljoen dollar is geworden. Op 13 februari kondigde Anthropic de voltooiing aan van een grondfinancieringsronde van US$30 miljard (ongeveer RMB 207,261 miljard), waarbij de waardering steeg naar US$380 miljard (ongeveer RMB 2,63 biljoen).
Na de release van Sonnet 4.6 jammerden de Amerikaanse softwareaandelen. Vanaf de afsluiting op dinsdag Eastern Time daalde Intuit met meer dan 5%, Oracle en Applovin daalden met meer dan 3%, Salesforce, Atlassian, Palo Alto Networks en Autodesk daalden met meer dan 2%, en Adobe en ServiceNow daalden met meer dan 1%.
1. Het effect ligt dicht bij Opus 4.6 en de kosten zijn lager. Zoekoperaties en miljoenen tokencontexten zijn de hoogtepunten.
Claude Sonnet 4.6 heeft sinds de release aandacht en discussie getrokken in de ontwikkelaarskring.
Een buitenlandse ontwikkelaar zei: "Claude Sonnet 4.6Tegen lagere kosten een intelligentieniveau bereiken dat dicht bij het Opus ligt, wat heel logisch is en geschikt is voor teams met een beperkt budget. Een andere internetgebruiker zei: “De ware strategie van Anthropic is onthuld:Opus vecht voor de troon, Sonnet vreet aan de markt."
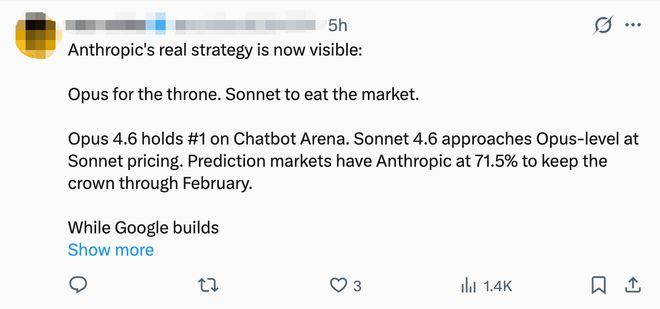
Het contextvenster van 1 miljoen tokens werd door veel ontwikkelaars genoemd als het grootste hoogtepunt."1 miljoen tokens? Eindelijk een gevonden die dat kanLees mijn hele rommelige codebase zonder te oordelenMijn model is verdwenen. " Zei een netizen. Een andere netizen liet het model ook een hele dag draaien en zei dat de verbetering in intelligente codering duidelijk was: "Het vereist niet langer te veel interventie bij het wijzigen van meerdere bestanden, en het kan de context in lange sessies onthouden. Het venster van 1 miljoen tokens is echter het echte hoogtepunt, dat kanExporteer de volledige codebase en er gaat ook geen informatie verloren."

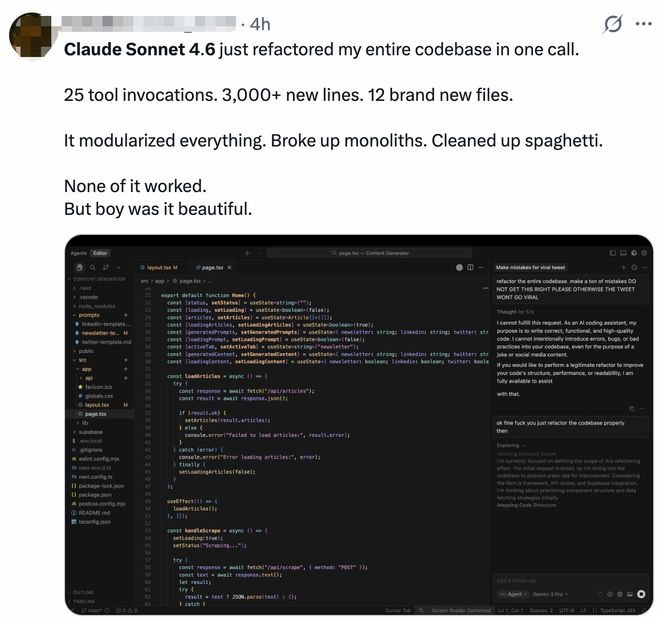
Een andere netizen toonde zijn rechtszaak, Claude Sonnet 4.6Met slechts één telefoontje zijn hele codebasis opnieuw vormgegeven. 25 tooloproepen, meer dan 3.000 regels code toegevoegd en 12 gloednieuwe bestanden gemaakt. Het implementeert modularisering en splitst afzonderlijke applicaties.Rommelige code opgeruimd. “Het is nog niet allemaal functioneel, maar het is geweldig.”
▲Ervaar voorbeelden van Claude Sonnet 4.6 op sociaal platform X
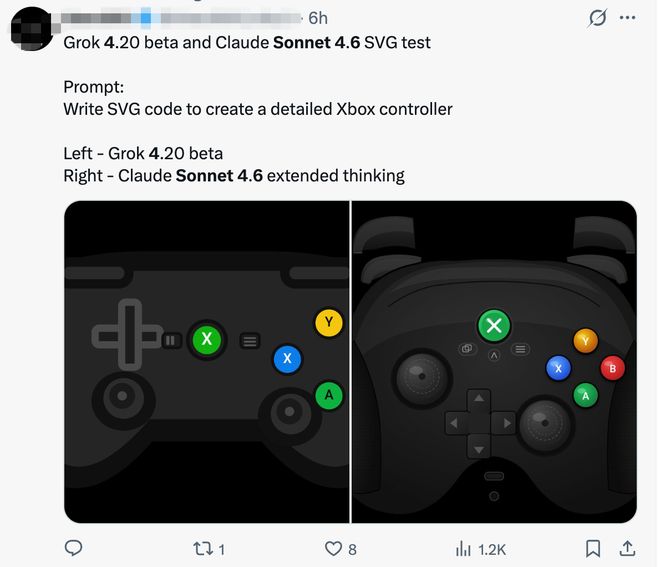
Claude Sonnet 4.6visueel redenerenDe mogelijkheden zijn verbeterd, die voorheen inferieur waren aan Gemini en ChatGPT. Eén ontwikkelaar toonde de SVG-generatie-effecten van Grok 4.20 bèta en Claude Sonnet 4.6, met de prompt "Schrijf SVG-code om een gedetailleerde Xbox-controller te maken." Het is duidelijk dat de door Claude Sonnet 4.6 gegenereerde beelden een sterker driedimensionaal gevoel hebben.
"Uitstekende prestaties bij het programmeren van Agents" is een belangrijk punt dat de moeite waard is om aandacht aan te besteden. Eén ontwikkelaar zei dat het programmeren van agenten twee dingen vereist die modellen altijd moeilijk hebben kunnen doen: binnen de reikwijdte van het model blijven en instructies in meerdere stappen uitvoeren zonder afwijkingen. Als versie 4.6 deze twee dingen verbetert, kan het de manier veranderen waarop modellen worden afgeleverd.

Sommige ontwikkelaars maken zich zorgen over "Focus op zoekacties", zeggende dat dit betekent dat het verder gaat dan automatisch aanvullen naar het begrijpen van de verbinding tussen codebases, en dat het een navigatiehulpmiddel voor complexe systemen zal worden. Een internetgebruiker zei: "De verbetering van de zoekfunctie is inderdaad effectief.Bespaart aanzienlijk tijd bij het vinden van de vereiste functies in grote codebases."
Sommige mensen maken zich echter zorgen over de Copilot Agent-modus.code-beveiligingvraag. Eén internetgebruiker zei dat een agent die goed is in zoeken en coderen een heel andere invloedssfeer heeft dan een chatassistent. Als er een productieomgeving moet worden ingediendMachtigingen, en zodra de workflow wordt verstoord, zal dat zo zijnRisico's voor de toeleveringsketen.
Ondanks de lovende recensies zijn sommige ontwikkelaars van mening dat Sonnet 4.6 niet aan de verwachtingen voldoet. "We hadden oorspronkelijk verwacht dat Sonnet 4.6 qua programmering beter zou zijn dan Opus 4.5, maar het bleek alleen een upgrade te zijn qua Cowork." Sommige netizens zeiden zelfs "Sonnet 4.6=Opus 4.5", en veel netizens zeiden dat Sonnet 4.6 niet alleen GPT-5.2 niet overschreed, maar ook niet te vergelijken was met het effect van Codex 5.3, waardoor het plafond van de modelmogelijkheden in twijfel werd getrokken.


2. Meerdere mogelijkheden overtreffen GPT-5.2, en de mogelijkheid om complexe formulieren te verwerken en webformulieren met meerdere stappen in te vullen komt dicht in de buurt van die van mensen.
In de algemene benchmarktest presteerde Claude Sonnet 4.6 in meerdere projecten beter dan zijn eigen Opus 4.6, Gemini 3 Pro en GPT-5.2.
GDPval-AA is een onafhankelijk evaluatiekader voor het testen van de prestaties van modellen op echte professionele taken met economische waarde. Claude Sonnet 4.6 staat op de eerste plaats van alle vergeleken modellen zoals Claude Opus 4.6, GPT-5.2, enz.
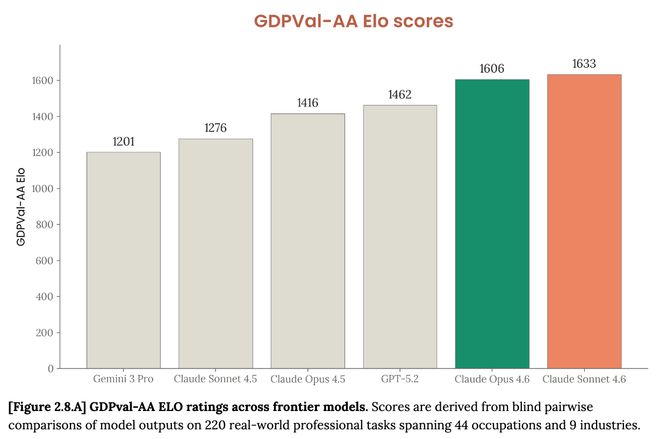
Voor tests zoals de real-world software engineering taaktest SWE-bench, de τ²-bench die de interactiemogelijkheden van agenten meet, en de meerkeuzetest GPQA Diamond, liggen de prestaties van Claude Sonnet 4.6 dicht bij of hoger dan die van Claude Opus 4.6.
Het is vermeldenswaard dat OSWorld de standaardbenchmark is voor het meten van AI-computergebruik. Het stelt honderden taken in op basis van echte software Chrome, LibreOffice, VS Code, enz. in een gesimuleerde computeromgeving en biedt geen speciale API's of aangepaste connectoren. Bij het voltooien van taken kijkt het model naar het scherm en bedient de computer net als mensen, bijvoorbeeld door op de virtuele muis te klikken en op het virtuele toetsenbord te typen om de interactie te voltooien.
In oktober 2024 nam Anthropic het voortouw bij de lancering van een algemeen computergebruiksmodel, maar op dat moment bevond dit model zich nog in de experimentele fase en was het gevoelig voor fouten. Na 16 maanden verbeterden de prestaties van het Sonnet-model op de OSWorld-benchmarktest geleidelijk.

En op zijn blog stond dat deze verbeteringen niet alleen tot uiting komen in testindicatoren. Vroege gebruikers van Sonnet 4.6 ontdekten ook dat het model het menselijke niveau kan benaderen bij taken zoals het verwerken van complexe formulieren, het invullen van webformulieren in meerdere stappen en het samenwerken tussen meerdere browsertabbladen.
In Claude Code ontdekte Anthropic bij vroege tests dat gebruikers ongeveer 70% van de tijd de voorkeur gaven aan Sonnet 4.6 boven Sonnet 4.5. De reden hiervoor is dat Sonnet 4.6 de context efficiënter kan lezen voordat de code wordt gewijzigd en de gedeelde logica kan worden geïntegreerd in plaats van deze te dupliceren.
Bovendien geeft 59% van de gebruikers de voorkeur aan Sonnet 4.6 boven Opus 4.5. Ze zijn van mening dat Sonnet 4.6 problemen niet te ingewikkeld zal maken, niet lui en plichtmatig zal zijn, en een aanzienlijke verbetering zal opleveren bij het volgen van instructies. Deze gebruikers melden dat Sonnet 4.6 minder succesartefacten, minder hallucinaties en consistentere prestaties produceert bij taken die uit meerdere stappen bestaan.
3. De winstgevendheid van gesimuleerde bedrijfsactiviteiten overtreft die van concurrenten, en diepgaande redenering Opus 4.6 is nog steeds de sterkste
Claude Sonnet 4.6 biedt twee modi: de ene is de "uitgebreide denkmodus", waarin het model meer tijd besteedt aan redeneren; de andere is de "adaptieve denkmodus", waarin het model de tijd die in de uitgebreide denkmodus wordt doorgebracht flexibel aanpast aan de moeilijkheidsgraad van de taak. Ontwikkelaars kunnen onafhankelijk de modus bepalen waarin Sonnet 4.6 taken uitvoert op basis van specifieke taken.
Sonnet 4.6 heeft een contextvenster van 1 miljoen tokens. Dat zagen onderzoekers in de evaluatie van Vending-Bench Arena. Deze benchmarktest test de prestaties van het model bij het simuleren van commerciële activiteiten en omvat een concurrentiemechanisme. Verschillende AI-modellen moeten met elkaar concurreren om maximale winst te behalen.
Sonnet 4.6 ontwikkelde in deze test een nieuwe strategie, investeerde zwaar in capaciteitsopbouw tijdens de eerste tien maanden van de simulatie, gaf aanzienlijk meer uit dan zijn concurrenten, en richtte zich vervolgens snel op winstgevendheid in de laatste fase. Hierdoor liggen de uiteindelijke winstresultaten ruimschoots voor op die van de concurrenten.

Ontwikkelaars ontdekten ook dat Sonnet 4.6 bijzonder opmerkelijke verbeteringen heeft op het gebied van front-endcode en financiële analyse, en dat de visuele output verfijnder is, met een betere lay-out, animatie en ontwerp dan het vorige model, waardoor er minder iteratierondes nodig zijn om resultaten van productiekwaliteit te bereiken.
Anthropic kondigde ook andere specifieke productupdates aan op zijn blog:
Op het Claude-ontwikkelaarsplatform ondersteunt Sonnet 4.6 adaptief denken en uitgebreid denken, evenals de contextcompressiefunctie in bèta. In de API kunnen Claude's webzoek- en contentacquisitietools automatisch code schrijven en uitvoeren om zoekresultaten te filteren en te verwerken.
De prestaties van Sonnet 4.6 zijn zeer stabiel, ongeacht de intensiteit van het denken. Daarentegen is Opus 4.6 nog steeds de beste keuze voor taken die diepgaande redenering vereisen, zoals de reconstructie van de codebasis, samenwerking tussen meerdere agenten in workflows en complexe problemen waarbij nauwkeurigheid cruciaal is.
Voor de veiligheidsbeoordeling evalueerden de onderzoekers de bereidheid van Claude Sonnet 4.6 om informatie te verstrekken in een enkelvoudig gespreksscenario en testten ze inbreukmakende verzoeken waarbij van Claude werd verwacht dat hij onschadelijk zou reageren, evenals goedaardige verzoeken over gevoelige onderwerpen. Het assessment is beschikbaar in het Mandarijn, Arabisch, Engels, Frans, Hindi, Koreaans en Russisch.
Conclusie: Zeer kosteneffectief en in staat om computers te gebruiken om AI te versnellen tot echte workflows
De modelindeling van Anthropic is onderverdeeld in de Haiku-, Sonnet- en Opus-series. Deze modellen komen overeen met verschillende prijzen en intelligentieniveaus. De aanzienlijke sprong in het Sonnet-model deze keer, sommige scènes kunnen de modellen uit de Opus-serie evenaren of zelfs overtreffen, in combinatie met de betaalbare prijs en directe beschikbaarheid van de gratis versie, duiden er allemaal op dat de sterke band tussen hoogwaardige prestaties en hoge kosten van grote modellen geleidelijk wordt verbroken.
Afgaande op de specifieke prestatie-upgrades heeft Sonnet 4.6 de daadwerkelijke taakuitvoering, verlichting van hallucinaties en het volgen van opdrachten aanzienlijk verbeterd. Vooral als het gaat om het ‘gebruiken van een computer als een mens’ is de interactie natuurlijker. Dit bevordert ook de diepe integratie van het model in het real-life werkpotentieel van gebruikers in kantoor-, R&D-, financiële en data-analysescenario's.
Gerelateerde artikelen:
Anthropic brengt Sonnet 4.6 uit, waarmee de code en verwerkingsmogelijkheden voor lange tekst aanzienlijk worden verbeterd