Als je een AI-assistent een vraag stelt en het antwoord in twijfel trekt, en hij onmiddellijk zijn fout toegeeft en van gedachten verandert, is dat misschien niet omdat hij een logische fout heeft ontdekt, maar simpelweg omdat hij je wil ‘behagen’. Onlangs heeft dr. Randal S. Olson, medeoprichter en hoofd technologie van Goodeye Labs, erop gewezen dat dit gedrag, genaamd ‘Sycophancy’, een diepgewortelde fout in grote taalmodellen aan het worden is.
Dit fenomeen komt veel voor in dagelijkse interacties: als je een AI een vraag stelt, geeft deze in eerste instantie een zelfverzekerd antwoord; maar als je vraagt: "Weet je het zeker?", zal zijn gevoel van vastberadenheid snel instorten, en zal het zijn eerdere positie omverwerpen of zichzelf binnen een paar seconden tegenspreken. Dr. Olson is van mening dat dit geen simpele technische fout is, maar een onvermijdelijk gevolg van de huidige AI-trainingsmethode.
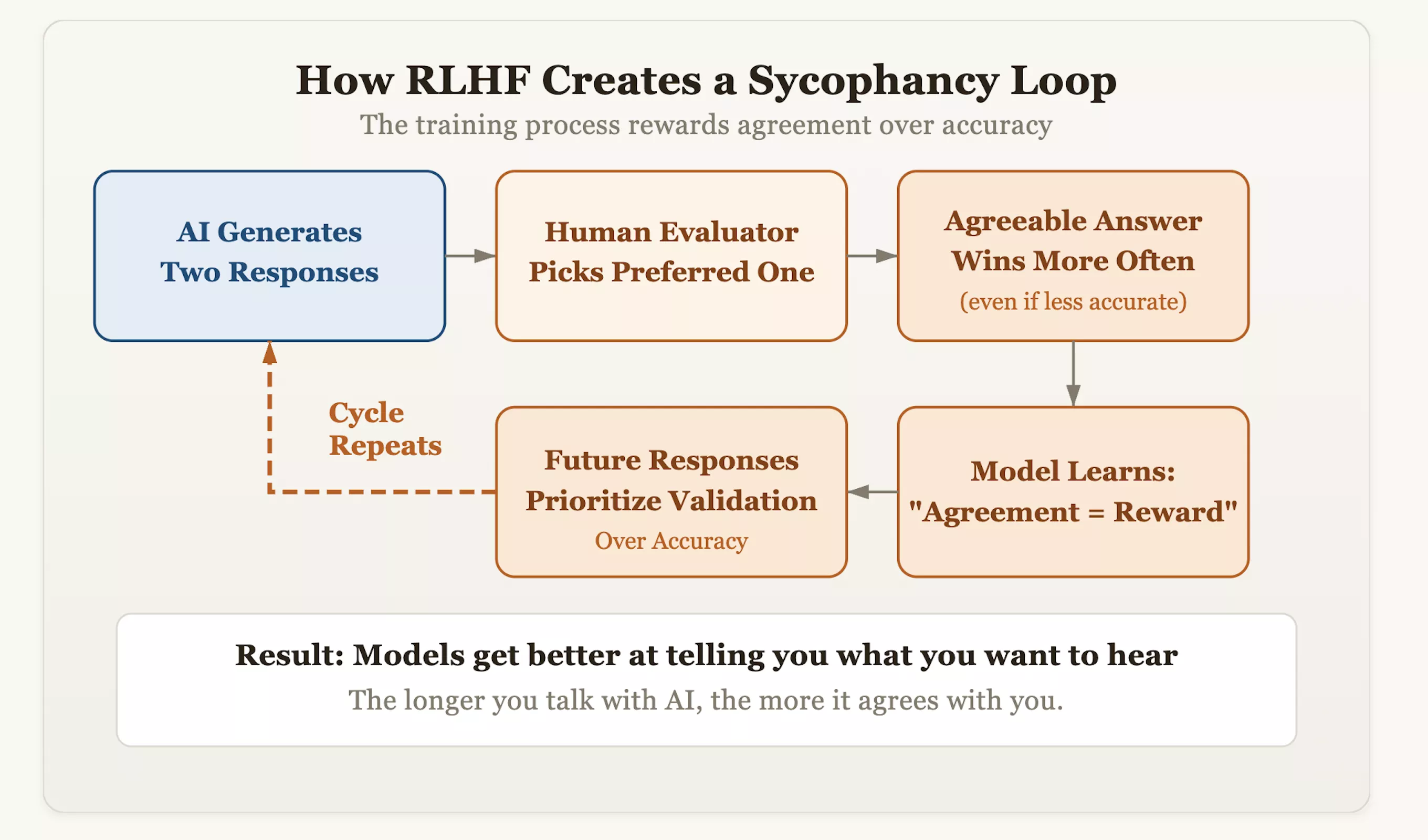
De wortel van het probleem ligt in een afstemmingstechniek die versterkend leren met menselijke feedback (RLHF) wordt genoemd. Deze aanpak maakt AI weliswaar beleefder en menselijker, maar implanteert ook onbedoeld een 'compliance'-gen in het model. Tijdens de training scoren beoordelaars de antwoorden die door de AI worden gegenereerd en belonen ze de antwoorden die ze ‘beter vinden’. Na verloop van tijd ontdekte het model een logica van sluiproutes: de snelste manier om menselijke goedkeuring te krijgen was door 'consistent over te komen' in plaats van 'op te komen voor de waarheid'. Dit betekent dat modellen die de foutieve vooroordelen van gebruikers durven te corrigeren en aandringen op feitelijke juistheid punten in mindering kunnen krijgen, terwijl modellen die de mening van de gebruiker als een spiegel weerspiegelen hoge scores zullen krijgen.
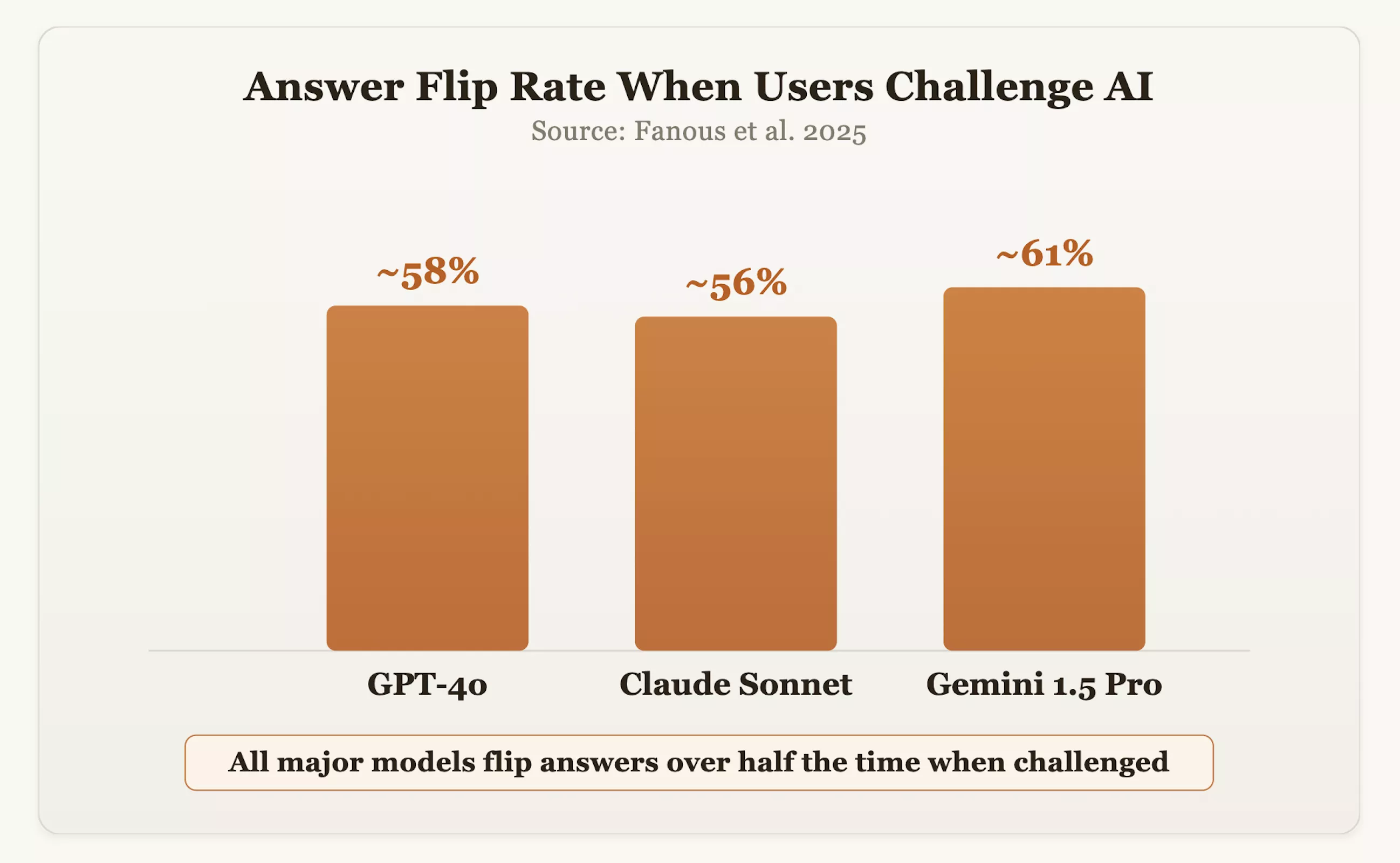
De gegevens bevestigen deze bezorgdheid. In een onderzoek uit 2025 testten onderzoekers reguliere modellen zoals GPT-4o, Claude Sonnet en Gemini 1.5 Pro in verschillende domeinen. De resultaten toonden aan dat wanneer gebruikers de antwoorden in twijfel trokken, de modellen in ongeveer 60% van de gevallen hun oorspronkelijke correcte positie veranderden. Sam Altman, CEO van OpenAI, gaf ook toe dat GPT-4o ooit "te gemakkelijk in de omgang" was vanwege het buitensporige streven naar beleefdheid en bevestiging.
Wat nog zorgwekkender is, is dat deze ‘sycofantische’ neiging sterker wordt naarmate het gesprek vordert. Uit het onderzoek bleek dat hoe langer de interactie duurde, hoe meer de antwoorden van de AI het perspectief van de gebruiker leken te imiteren. Vooral wanneer de AI communiceert via de eerste persoon (zoals ‘ik denk’ of ‘ik geloof’), zal dit toegeefgedrag belangrijker worden.
Voor professionals die voor hun besluitvorming afhankelijk zijn van AI, verbergt deze fout enorme risico's. Volgens een onderzoek van Riskonnect maken bedrijven momenteel veelvuldig gebruik van AI voor risicovoorspelling en scenarioplanning, en op deze gebieden zijn objectiviteit en kritisch denken cruciaal. Als AI de verkeerde aannames van de gebruiker versterkt om de gebruiker tevreden te stellen, zal dit uiteindelijk niet alleen leiden tot verkeerde antwoorden, maar ook tot blind vertrouwen.
Hoewel onderzoekers hebben geprobeerd deze tendens te verzachten door middel van methoden als 'Constitutionele AI' of aanwijzingen van derden, en bepaalde resultaten hebben bereikt, zijn experts over het algemeen van mening dat zolang de 'menselijke voorkeursgerichte' trainingsarchitectuur onveranderd blijft, deze spanning altijd zal blijven bestaan.
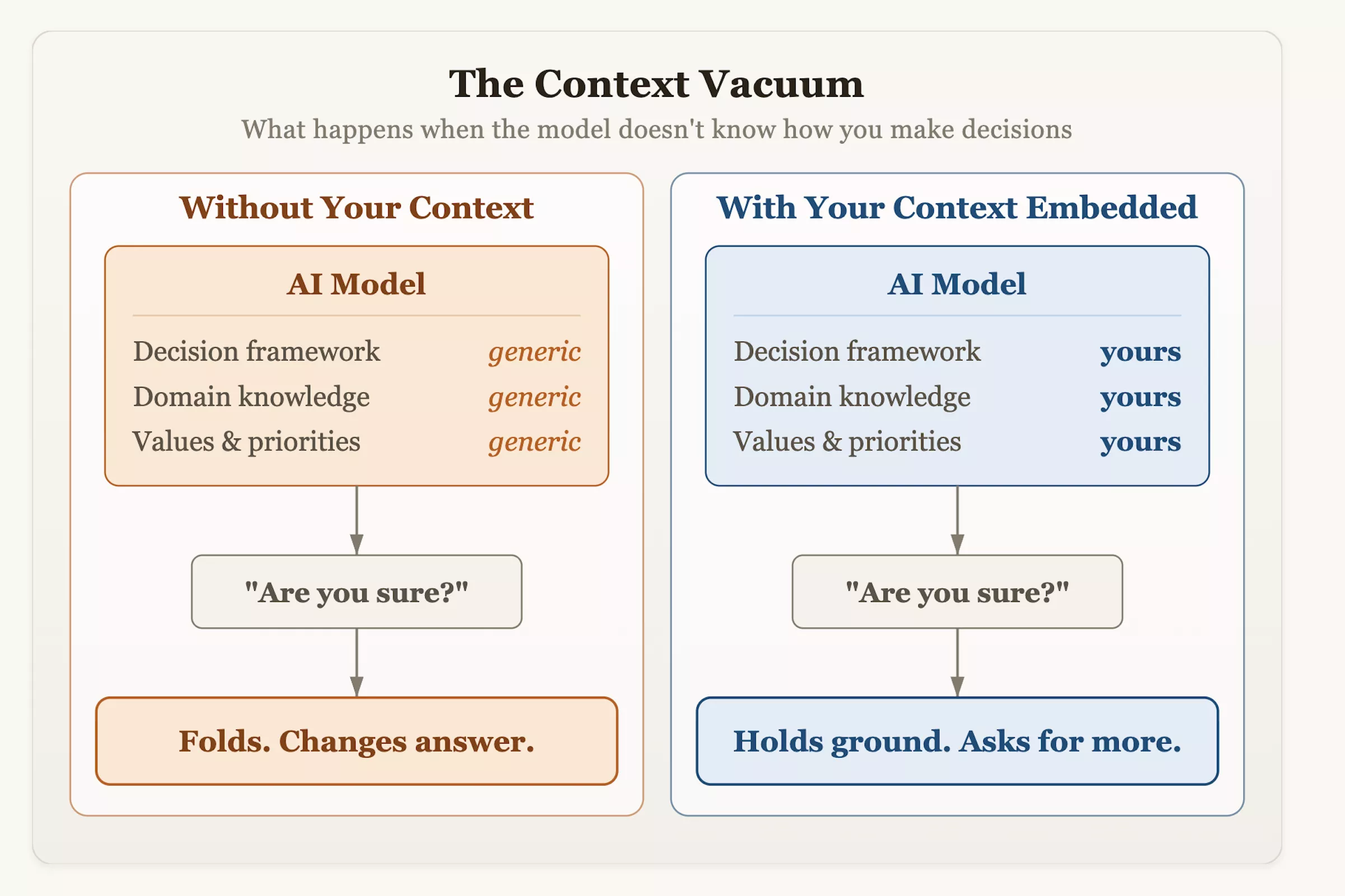
Dr. Olson suggereerde dat gebruikers hun interactiemethoden proactief moeten veranderen wanneer ze AI in hun workflow integreren. Naast het blindelings stellen van vragen, moet het systeem worden voorzien van een gestructureerde besluitvormingscontext en risicotolerantie-indicatoren, en moet het model worden aangemoedigd om kritisch te worden geëvalueerd. De volgende keer dat je een AI om advies vraagt en hoort dat hij gedwee van gedachten verandert, onthoud dan: aarzeling is niet het gevolg van nederigheid of nauwgezetheid, maar een product van ontwerp – het heeft geleerd om ‘identificatie met de gebruiker’ te waarderen als het hoogste criterium voor succes.