Zojuist heeft DeepSeek zijn speciale model DeepSeek-OCR 2 voor OCR-scenario's open source beschikbaar gesteld, en tegelijkertijd is het technische rapport vrijgegeven. Dit model is een upgrade van het DeepSeek-OCR-model van vorig jaar.Dankzij de nieuwe decoder die het model gebruikt, kan het model afbeeldingen bekijken en bestanden lezen als een mens, in plaats van als een mechanische scanner.
Simpel gezegd: de vorige modelleesmodus bestaat uit het scannen van de afbeelding van linksboven naar rechtsonder, terwijl DeepSeek-OCR 2 de structuur kan begrijpen en deze stap voor stap kan lezen volgens de structuur. Deze nieuwe manier van visueel begrijpen,Laat DeepSeek-OCR 2 complexe lay-outreeksen, formules en tabellen beter begrijpen.
Op de documentbegripbenchmark OmniDocBench v1.5 behaalde DeepSeek-OCR 2 de91,09%De score van , ervan uitgaande dat de trainingsgegevens en de encoder ongewijzigd blijven,Verbeterd met 3,73% vergeleken met DeepSeek-OCR. Vergeleken met andere end-to-end OCR-modellen is dit wel het gevalSOTA-resultaten, maar de prestaties zijn iets minder dan die van Baidu's PaddleOCR-VL (92,86%) OCR-pijplijn.
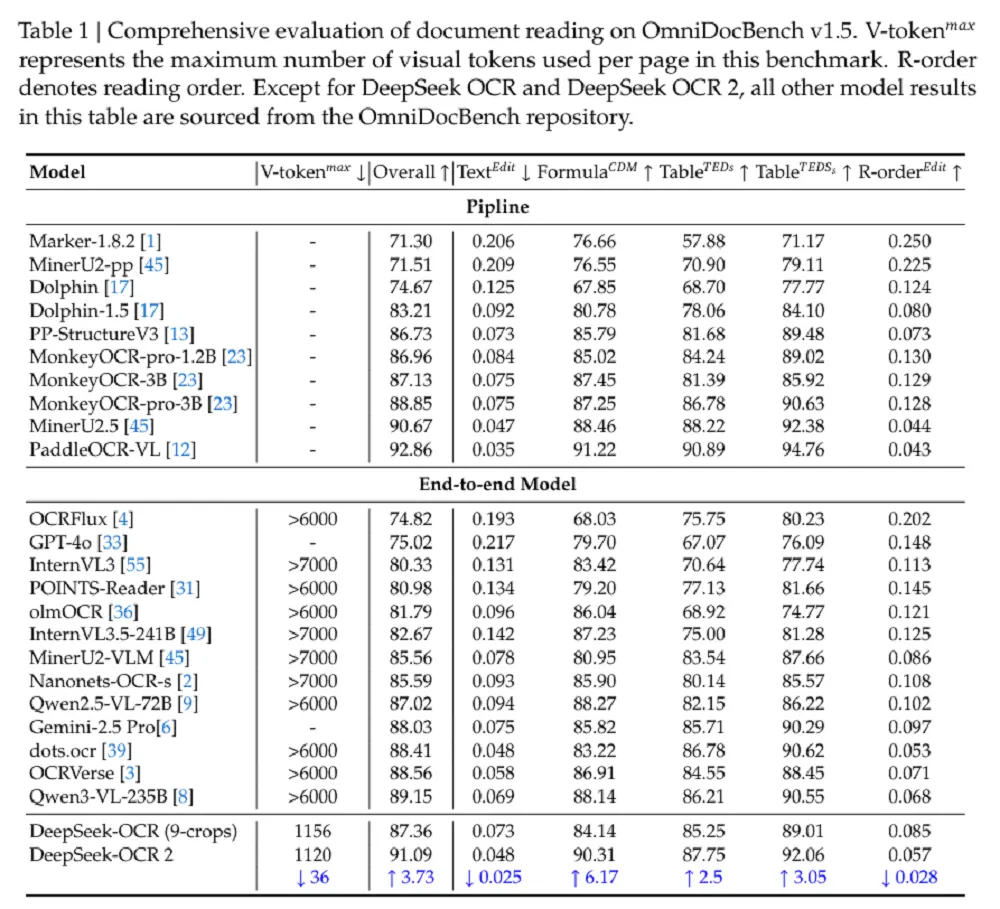
Tegelijkertijd, onder een vergelijkbaar visueel tokenbudget,DeepSeek-OCR 2 heeft een lagere bewerkingsafstand (de hoeveelheid werk die nodig is om tekst te bewerken) bij het parseren van documenten dan Gemini-3 Pro, wat bewijst dat DeepSeek-OCR 2 een hoge compressiesnelheid van visuele tokens handhaaft en tegelijkertijd superieure prestaties garandeert.
DeepSeek-OCR 2 biedt dubbele waarde: als beideVerkennend onderzoek naar nieuwe VLM-architectuur (Visual Language Model)., kan ook worden gebruikt als een praktisch hulpmiddel om hoogwaardige pre-trainingsgegevens te genereren ten behoeve van het trainingsproces van grote taalmodellen.
Papieren link:
https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
Open source-adres:
https://github.com/deepseek-ai/DeepSeek-OCR-2?tab=readme-ov-file
01.
Begrijp je de complexe bestandsstructuur van een groot model niet?
Observeer eerst de algemene situatie en lees dan om het probleem op te lossen
Vanuit architectonisch oogpunt erft DeepSeek-OCR 2 de algehele architectuur van DeepSeek-OCR, die bestaat uit een encoder en een decoder. De encoder discretiseert afbeeldingen in visuele tokens, en de decoder genereert uitvoer op basis van deze visuele tokens en tekstuele aanwijzingen.
Het belangrijkste verschil is de encoder: DeepSeek heeft de vorige DeepEncoder geüpgraded naar DeepEncoder V2, die alle oorspronkelijke mogelijkheden behoudt, maar de originele op CLIP gebaseerde encoder vervangt door een op LLM gebaseerde encoder.Tegelijkertijd wordt causaal redeneren geïntroduceerd via een nieuw architectonisch ontwerp.
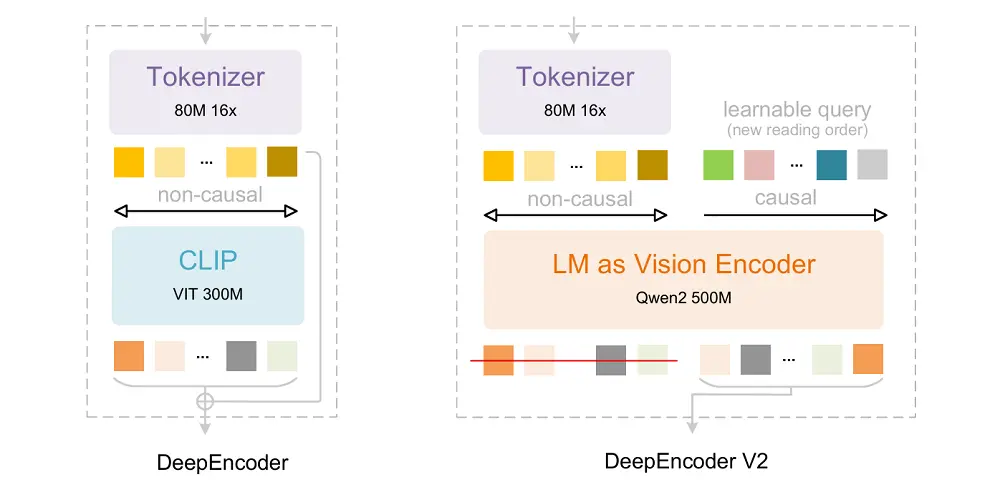
Het kernprobleem waar DeepEncoder V2 zich op richt is dat wanneer een tweedimensionale structuur wordt toegewezen aan een eendimensionale reeks en gebonden is aan een lineaire volgorde, het model onvermijdelijk wordt beïnvloed door de volgorde bij het modelleren van ruimtelijke relaties.
Dit kan acceptabel zijn in natuurlijke beelden, maar inIn scenario's met complexe lay-outs zoals OCR, tabellen, formulieren, enz., komt de lineaire volgorde vaak ernstig niet overeen met de werkelijke semantische organisatie, waardoor het vermogen van het model om de visuele structuur uit te drukken wordt beperkt.
Hoe verhelpt DeepEncoder V2 dit probleem? Het maakt eerst gebruik van een visuele tokenizer om afbeeldingen efficiënt weer te geven, en bereikt ongeveer 16 keer tokencompressie via vensteraandacht. Het vermindert de daaropvolgende globale aandachtsberekening en geheugenoverhead aanzienlijk, terwijl er voldoende lokale en mesoschaal visuele informatie behouden blijft.
Het is niet afhankelijk van positionele codering om de semantische volgorde van visuele tokens te specificeren, maar introduceertcausale vragen, het opnieuw ordenen en distilleren van visuele markeringen via inhoudbewuste methoden. Deze volgorde wordt niet bepaald door regels voor ruimtelijke expansie,In plaats daarvan wordt het stap voor stap door het model gegenereerd na observatie van de globale visuele context, waardoor een sterke afhankelijkheid van een vaste eendimensionale orde wordt vermeden.
Elke causale zoekopdracht kan zich richten op alle visuele tokens en eerdere zoekopdrachten, waardoor visuele kenmerken semantisch opnieuw worden geordend en informatie wordt gedistilleerd, terwijl het aantal tokens ongewijzigd blijft. Ten slotte wordt alleen de uitvoer van de causale vraag naar de stroomafwaartse LLM-decoder gevoerd.
Dit ontwerp vormt in wezen een causaal inferentieproces op twee niveaus: ten eerste sorteert de encoder intern semantisch ongeordende visuele tokens door middel van causale vragen. Vervolgens voert de LLM-decoder autoregressieve gevolgtrekking uit op deze geordende reeks.
In plaats van ruimtelijke ordening te forceren via positionele codering,De volgorde die wordt veroorzaakt door causale vragen is meer consistent met de visuele semantiek zelf, dat wil zeggen, het is in lijn met de normale gewoonten van mensen die inhoud lezen.
Omdat DeepSeek-OCR 2 zich voornamelijk richt op encoderverbeteringen, zijn er geen upgrades voor de decodercomponent. Volgens dit ontwerpprincipe behoudt DeepSeek de DeepSeek-OCR-decoder: een MoE-structuur met 3B-parameters met ongeveer 500 miljoen actieve parameters.
02.
OmniDocBench scoorde 91,09%
Bewerk afstand lager dan Gemini-3 Pro
Om de effectiviteit van het bovenstaande ontwerp te verifiëren, heeft DeepSeek experimenten uitgevoerd. Het onderzoeksteam heeft DeepSeek-OCR 2 in drie fasen getraind:Vooropleiding voor encoders, verbetering van zoekopdrachten en specialisatie van decoders.
In de eerste fase kunnen visuele tokenizers en encoders in LLM-stijl basismogelijkheden verwerven voor het extraheren van functies, tokencompressie en het opnieuw ordenen van tokens. De tweede fase verbetert de mogelijkheden van de encoder voor het herschikken van tokens en verbetert de compressie van visuele kennis. De derde fase bevriest de encoderparameters en optimaliseert alleen de decoder, waardoor een hogere datadoorvoer op dezelfde FLOP's wordt bereikt.
Om het modeleffect te evalueren, heeft DeepSeek OmniDocBench v1.5 gekozen als de belangrijkste evaluatiebenchmark. De benchmark bevat 1.355 documentpagina's die 9 hoofdcategorieën in het Chinees en Engels bestrijken (waaronder tijdschriften, academische artikelen, onderzoeksrapporten, enz.).
DeepSeek-OCR 2 behaalde een prestatie van 91,09% met alleen de kleinste visuele token-bovengrens (V-token maxmax). Vergeleken met de DeepSeek-OCR-basislijn laat het, onder vergelijkbare trainingsgegevensbronnen, een verbetering zien van 3,73%, wat de effectiviteit van de nieuwe architectuur verifieert.
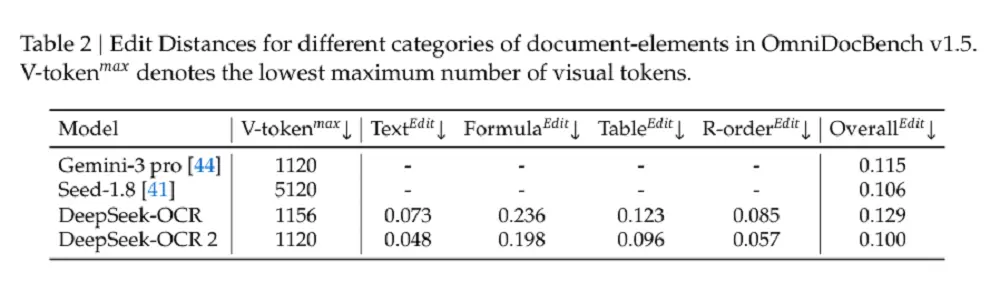
Naast de algehele verbetering is ook de bewerkingsafstand (ED) van de leesvolgorde (R-volgorde) aanzienlijk gedaald (van 0,085 naar 0,057),Dit toont aan dat de nieuwe DeepEncoder V2 initiële visuele markeringen effectief kan selecteren en rangschikken op basis van beeldinformatie.
Met een vergelijkbaar visueel opmaakbudget (1120) bereikt DeepSeek-OCR 2 (0,100) een lagere bewerkingsafstand bij het parseren van documenten dan Gemini-3 Pro (0,115), wat verder bewijst dat het nieuwe model prestaties garandeert terwijl een hoge compressiesnelheid voor visuele opmaak behouden blijft.
DeepSeek-OCR 2 is echter niet almachtig.Op kranten met een extreem hoge tekstdichtheid is het herkenningseffect van DeepSeek-OCR 2 niet zo goed als bij andere soorten tekst.Dit probleem kan later worden opgelost door het aantal lokale knipsels te vergroten of door tijdens het trainingsproces meer monsters aan te bieden.
03.
Conclusie: Het kan het begin zijn van een nieuwe VLM-architectuur
DeepEncoder V2 biedt voorlopige verificatie van de haalbaarheid van LLM-stijl encoders voor visuele taken. Belangrijker nog is dat het onderzoeksteam van DeepSeek gelooft dat deze architectuur het potentieel heeft om te evolueren naar een uniforme encoder voor alle modaliteiten. Zo'n encoder kan tekst comprimeren, spraakkenmerken extraheren en visuele inhoud reorganiseren binnen dezelfde parameterruimte.
DeepSeek zei dat de optische compressie van DeepSeek-OCR een eerste verkenning van native multimodaliteit vertegenwoordigt. In de toekomst zullen ze de integratie van aanvullende modaliteiten via dit gedeelde encoderframework blijven onderzoeken, wat het begin zal worden van een nieuwe VLM-architectuur voor onderzoek en verkenning.