Van wereldwijde populariteit tot succesvolle financiering, tot het feit dat hij werd blootgesteld aan het verwijderen van blogs, ontslagen en het weglopen naar Singapore: Manus had slechts vier maanden nodig om het ondernemerschap van een opkomend circuit te demonstreren. Sommige mensen denken dat Manus een slechte start heeft gemaakt door gebruik te maken van Chinese technische middelen om producten te bouwen, snel fondsen te werven, werknemers te ontslaan en weg te lopen... Te midden van de controverse, in de vroege uren van deze ochtend, sprak de mede-oprichter van het bedrijf, Ji Yichao, zich zelden uit en publiceerde een blog van enkele duizenden woorden in een poging de publieke opinie terug te brengen naar het product en de technologie zelf. Hij reageerde ook voor het eerst publiekelijk op de belangrijkste lessen achter deze ups en downs.

Van explosie tot controverse in vier maanden
Laten we het eerst kort bekijken. In maart van dit jaar werd Manus populair vanwege zijn concept van 'de eerste universele agent ter wereld'. Sommige mensen zeiden destijds dat dit China's "tweede DeepSeek-moment" was.
In mei rondde Manus snel een Series B-financieringsronde van $75 miljoen af onder leiding van de beste durfkapitaalbenchmark van Silicon Valley, waarbij de waardering steeg tot $500 miljoen. De buitenwereld had er extreem hoge verwachtingen van.
Eind juni werd Manus echter plotseling door de media blootgesteld aan veel controversiële incidenten: sommige werknemers beweerden zonder waarschuwing te zijn ontslagen, het oprichtersteam verwijderde op grote schaal hun blogs op sociale platforms en het hoofdorgaan van het bedrijf verhuisde naar Singapore, wat publieke verontwaardiging veroorzaakte.
Een tijdlang werden het verwijderen van blogs, ontslagen en weglopen de belangrijkste labels van dit startende bedrijf met sterrenagenten.
De mede-oprichter plaatste in de vroege ochtend een lange post
Ondanks externe twijfels besloot Ji Yichao deze keer te antwoorden met een lang technisch artikel, waarin voor het eerst systematisch de kernkennis van het team over Agent-producten en -technologieën werd samengevat:
1. Kies voor contextuele engineering in plaats van end-to-end zelf ontwikkelde grote modellen. De oprichter van Manus probeerde in zijn vorige bedrijf een NLP-model helemaal opnieuw te trainen, maar werd geëlimineerd door grote modellen zoals GPT-3. Na deze evaluatie kozen ze ervoor om het onderliggende model niet zelf te ontwikkelen, maar zich te concentreren op hoe ze aan "contextuele engineering" konden doen op basis van open source of grote commerciële modellen om hun bestaande mogelijkheden te maximaliseren.
2. KV cache hit rate is de kernindicator van het proxysysteem. Intelligente agenten met meerdere rondes zijn anders dan chats met één ronde. De input-output-verhouding kan oplopen tot 100:1, en lange inputs hebben een grote invloed op de latentie- en gevolgtrekkingskosten. Het doel van contextontwerp is om de hitrate van de KV-cache te maximaliseren, wat vereist dat de prompt stabiel is, dat de context wordt toegevoegd maar niet wordt gewijzigd, en dat het voorvoegsel opnieuw wordt gebruikt.
3. Gereedschapsbeheer vermijdt dynamisch toevoegen en verwijderen en gebruikt maskeren in plaats van verwijderen. Met veel agentfuncties zal de actieruimte snel uitbreiden, waardoor het gemakkelijker wordt om het verkeerde model te kiezen. Het dynamisch toevoegen of verwijderen van tools kan cache-invalidatie veroorzaken. De praktijk van Manus is om contextstatusmachines te gebruiken om de beschikbaarheid van tools te beheren: door de Token-waarschijnlijkheid af te schermen in plaats van deze direct uit de context te verwijderen, zorgt het niet alleen voor flexibiliteit, maar behoudt het ook de cache.
4. Behandel het bestandssysteem als een oneindige context. Hoe groot het contextvenster van een groot model ook is, het is beperkt, en een zeer lange context zal de gevolgtrekkingssnelheid vertragen en de kosten verhogen. De aanpak van Manus is om het bestandssysteem te behandelen als het externe geheugen van de agent. Informatie is op elk moment toegankelijk, waardoor de historische status kan worden gecontroleerd, gelezen, geschreven en hersteld.
5. Gebruik een expliciet ‘recitatie’-mechanisme om de aandacht van het model te controleren. Bij lange taken genereert Manus automatisch todo.md, splitst de taak op in een lijst met uitvoerbare bestanden en werkt deze voortdurend bij. Het doel wordt herhaaldelijk aan het einde van de context geschreven, wat gelijk staat aan "herhaaldelijk herinneren aan het model" om te voorkomen dat de taak halverwege uit de hand loopt.
6. Wis geen fouten en bewaar foutinformatie om het model te helpen zichzelf te corrigeren. De agent zal zeker fouten maken. In plaats van fouten te verbergen en opnieuw te beginnen, is het beter om de foutinformatie in de context te laten en het model het foutpad te laten 'zien' om negatieve voorbeelden te vormen, waardoor soortgelijke fouten worden verminderd.
7. Samenvattend in één zin: Context engineering is een opkomende experimentele wetenschap. Manus wil context gebruiken om het gedrag en de mogelijkheden van agenten vorm te geven: het is geen competitie om te zien hoe slim het model is, maar een competitie om het model bruikbaarder te maken.
Na de herziening is de controverse niet verdwenen
Uit deze blog blijkt dat Manus niet geheel een “PPT-project” is. Het heeft inderdaad veel verkenningen op laag niveau gedaan voor agentscenario's, en heeft ook veel valkuilen overwonnen.
Maar in dit lange artikel werd niet de vraag genoemd waar de buitenwereld zich het meest zorgen over maakt: waarom verhuisde het bedrijf naar Singapore? Hoe gaan binnenlandse ontslagen werknemers om met de nasleep? enz.
Ji Yichao beantwoordde deze vragen niet en vermeldde ze ook niet in zijn blog.
Ji Yichao schreef aan het einde: "De toekomst van intelligente agenten zal geleidelijk één voor één worden opgebouwd. Elke situatie wordt zorgvuldig ontworpen."
De huidige realiteit is: heeft Manus nog steeds de kans om deze ‘scenario’s’ uit technische documenten terug te brengen naar echte gebruikers?
Er is nog niets geregeld.
Link naar blogpost:
https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus

Het volgende is de originele blogpost van Manus mede-oprichter Ji Yi (vertaald door GPT):
Context-engineering voor AI-agenten: lessen die zijn geleerd bij het bouwen van Manus
18 juli 2025 Ji Yichao
Aan het begin van het Manus-project stonden mijn team en ik voor een belangrijke beslissing: moeten we een open source basismodel gebruiken om een end-to-end agentmodel te trainen, of moeten we een agent bouwen op basis van de contextuele leermogelijkheden van geavanceerde modellen?
Als ik terugdenk aan mijn eerste tien jaar in natuurlijke taalverwerking, hadden we die keuze niet. In de oude tijd van BERT (ja, het is zeven jaar oud) moesten modellen worden verfijnd en geëvalueerd voordat ze werden overgedragen aan nieuwe taken. Hoewel de modellen toen veel kleiner waren dan de huidige LLM's, duurde dit proces vaak weken per iteratie. Voor zich snel ontwikkelende toepassingen, vooral in de vroege stadia van product-markt-fit, is een dergelijke langzame feedbackcyclus fataal. Dit was een les die ik op de harde manier heb geleerd bij mijn laatste startup, toen ik modellen helemaal opnieuw trainde voor open informatie-extractie en semantisch zoeken. Toen maakte de opkomst van GPT-3 en Flan-T5 mijn zelfontwikkelde model van de ene op de andere dag irrelevant. Ironisch genoeg zijn het deze modellen die een nieuw tijdperk van contextueel leren inluiden – en ons een geheel nieuw pad voorwaarts geven.
Deze zwaarbevochten les maakte de keuze duidelijk: Manus zou inzetten op contextuele engineering. Hierdoor kunnen we verbeteringen binnen enkele uren in plaats van weken vrijgeven, terwijl we ons product orthogonaal houden ten opzichte van het onderliggende model: als de voortgang van het model een opkomend tij was, wilden we dat Manus een schip zou zijn, en geen pilaar die verankerd was aan de zeebodem.
Context-engineering is echter verre van eenvoudig. Dit is een experimentele wetenschap: we hebben het agency-framework vier keer opnieuw opgebouwd, elke keer nadat we een betere manier hadden ontdekt om de context vorm te geven. We noemen dit handmatige proces van zoeken naar architectuur, het afstemmen van hints en empirisch raden liefkozend 'stochastische gradiëntafdaling'. Het is niet elegant, maar het werkt.
Dit bericht deelt de lokale optimale oplossing die we hebben bereikt via onze eigen "SGD". Als u uw eigen AI-agent bouwt, zullen deze principes u hopelijk helpen sneller samen te komen.
Ontworpen rond KV-cache
Als ik maar één statistiek zou kunnen kiezen, denk ik dat het KV-cache-hitpercentage de belangrijkste statistiek is voor AI-agents in de productiefase. Het heeft rechtstreeks invloed op de latentie en de kosten. Om te begrijpen waarom, laten we eerst kijken hoe een typische proxy werkt:
Na ontvangst van gebruikersinvoer voltooit de agent de taak via een reeks tooloproepen. In elke iteratie selecteert het model een actie uit een vooraf gedefinieerde actieruimte op basis van de huidige context. De actie wordt vervolgens uitgevoerd in een omgeving (zoals de sandbox van de virtuele machine van Manus) om observaties te produceren. Acties en observaties worden aan de context toegevoegd en vormen de input voor de volgende iteratie. Deze cyclus gaat door totdat de taak is voltooid.
Zoals u zich kunt voorstellen, groeit de context met elke stap, terwijl de uitvoer (meestal een gestructureerde functieaanroep) relatief kort is. Hierdoor is de verhouding tussen prepopulatie en decodering bij agenten veel hoger, in tegenstelling tot chatbots. In Manus is de gemiddelde input-to-output-tokenverhouding bijvoorbeeld ongeveer 100:1.
Gelukkig kunnen contexten met hetzelfde voorvoegsel profiteren van KV-caching, waardoor de tijd tot de eerste tokenisatie (TTFT) en de gevolgtrekkingskosten aanzienlijk worden verminderd, ongeacht of u een zelfgehost model gebruikt of de inferentie-API aanroept. De besparingen zijn hier niet klein: in het geval van Claude Sonnet kosten in de cache opgeslagen invoertags $ 0,30/duizend tags, vergeleken met $ 3/duizend niet in de cache opgeslagen - een verschil van 10x.
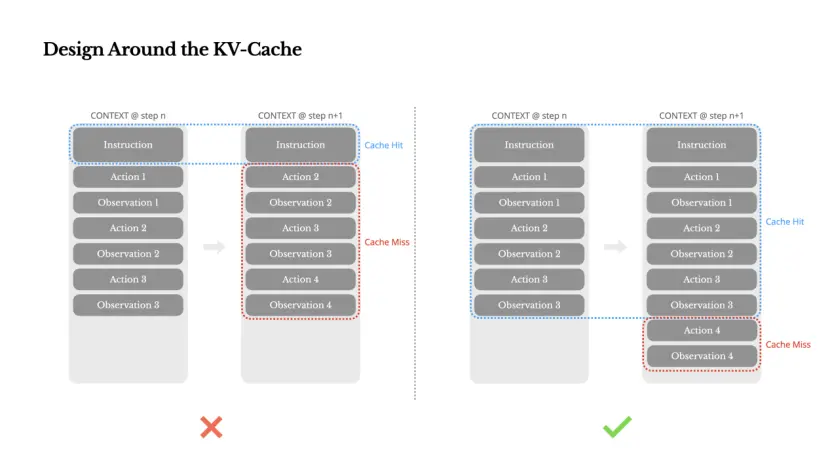
Vanuit een perspectief van contexttechniek omvat het verbeteren van het aantal KV-cachehits verschillende belangrijke praktijken:
Houd het promptvoorvoegsel stabiel. Vanwege de autoregressieve aard van LLM's zullen verschillen in zelfs een enkele tag die tag en daaropvolgende caches ongeldig maken. Een veel voorkomende fout is het plaatsen van een tijdstempel aan het begin van de systeemprompt, vooral een tijdstempel die tot op de seconde nauwkeurig is. Hoewel dit het model in staat stelt u de huidige tijd te vertellen, wordt het aantal cachehits aanzienlijk verlaagd.
Zorg ervoor dat uw context alleen wordt toegevoegd. Vermijd het wijzigen van eerdere acties of observaties. Zorg ervoor dat uw serialisatie deterministisch is. Veel programmeertalen en bibliotheken garanderen geen stabiele volgorde van sleutels bij het serialiseren van JSON-objecten, wat stilletjes caches kan beschadigen.
Markeer cache-breekpunten expliciet wanneer dat nodig is. Sommige modelaanbieders of inferentieframeworks ondersteunen geen automatische verhoging van voorvoegselcaching en vereisen in plaats daarvan handmatige invoeging van cachebreekpunten in de context. Wanneer u deze breekpunten instelt, moet u rekening houden met de mogelijkheid dat de cache verloopt en er in ieder geval voor zorgen dat het breekpunt het einde van de systeemprompt omvat.
Als u bovendien een zelf-hostend raamwerkmodel zoals vLLM gebruikt, zorg er dan voor dat u prefix/hint-caching inschakelt en technieken zoals sessie-ID's gebruikt om aanvragen consistent door gedistribueerde werkknooppunten te routeren.
Masker, niet verwijderen
Naarmate uw agent krachtiger wordt, wordt zijn actieruimte uiteraard complexer – kortom: het aantal tools neemt toe. De recente populariteit van MCP heeft alleen maar olie op het vuur gegooid. Als je gebruikers toestaat tools aan te passen, geloof me dan: iemand zal honderden mysterieuze tools in je zorgvuldig samengestelde actieruimte pluggen. Als gevolg hiervan is de kans groter dat het model de verkeerde actie kiest of een inefficiënt pad bewandelt. Kortom, uw herladen agent wordt dommer.
Een natuurlijke reactie zou het ontwerpen van een dynamische actieruimte zijn - misschien met behulp van een RAG-achtige aanpak om gereedschappen op verzoek te laden. Wij hebben dit ook geprobeerd in Manus. Maar experimenten laten een duidelijke regel zien: vermijd het dynamisch toevoegen of verwijderen van tools tijdens een iteratie, tenzij dit absoluut noodzakelijk is. Er zijn twee belangrijke redenen:
In de meeste LLM's bevinden gereedschapsdefinities zich meestal vooraan in de context na serialisatie, meestal vóór of na de systeemprompt. Daarom zullen eventuele wijzigingen de KV-cache ongeldig maken voor alle volgende bewerkingen en observaties.
Modellen raken in de war als eerdere acties en observaties nog steeds verwijzen naar instrumenten die in de huidige context niet langer gedefinieerd zijn. Zonder beperkte decodering resulteert dit vaak in patroonovertredingen of illusoire operaties.
Om dit probleem op te lossen en de effectiviteit van actieselectie te verbeteren, gebruikt Manus een contextbewuste statusmachine om de beschikbaarheid van tools te beheren. Het is geen verwijderingstool, maar maskeert eerder de logwaarschijnlijkheid van het token tijdens het decoderen om te voorkomen (of te forceren) dat bepaalde acties worden geselecteerd op basis van de huidige context.
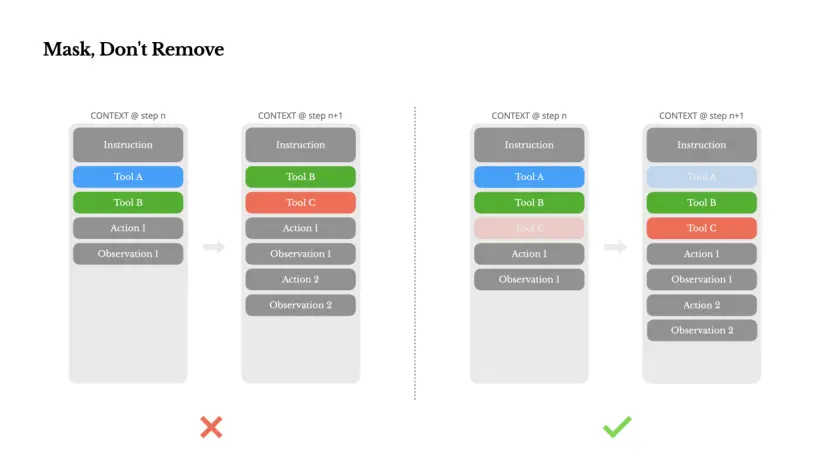
In de praktijk ondersteunen de meeste modelaanbieders en inferentiekaders een vorm van respons-prepopulatie, waardoor u de actieruimte kunt beperken zonder de tooldefinitie te wijzigen. Functieaanroepen hebben doorgaans drie modi (we nemen het Hermes-formaat van NousResearch als voorbeeld):
Automatisch – Het model kan kiezen of de functie wordt aangeroepen. Geïmplementeerd door alleen het antwoordvoorvoegsel vooraf in te vullen: <|im_start|>assistent
Vereist - Het model moet een functie aanroepen, maar de selectie is niet beperkt. Geïmplementeerd door het vooraf invullen van de toolaanroeptag: <|im_start|>assistent
Opgegeven: het model moet functies uit een specifieke subset aanroepen. Dit wordt bereikt door de functienaam vooraf in te vullen: <|im_start|>assistant{"name": “browser_
Met deze aanpak beperken we de actieselectie door de logwaarschijnlijkheid van markers direct te maskeren. Wanneer de gebruiker bijvoorbeeld nieuwe invoer geeft, moet Manus onmiddellijk reageren in plaats van een actie uit te voeren. We hebben ook doelbewust actienamen zo ontworpen dat ze consistente voorvoegsels hebben. Alle browsergerelateerde tools beginnen bijvoorbeeld met browser_, en opdrachtregelprogramma's beginnen met shell_. Hierdoor kunnen we er eenvoudig voor zorgen dat een agent alleen kiest uit een bepaalde set instrumenten in een specifieke staat, zonder gebruik te maken van een stateful log-probability processor.
Deze ontwerpen zorgen ervoor dat de Manus-agentlus stabiel blijft, zelfs onder modelgestuurde architecturen.
Gebruik het bestandssysteem als context
Moderne geavanceerde LLM's bieden nu contextvensters van 128.000 tokens of meer. Maar in realistische scenario's met intelligente agenten is dit vaak niet genoeg en wordt het soms zelfs een last. Er zijn drie veelvoorkomende pijnpunten:
Waarnemingen kunnen erg groot zijn, vooral wanneer agenten interactie hebben met ongestructureerde gegevens zoals webpagina's of pdf's. Het is gemakkelijk om contextuele grenzen te overschrijden.
Zelfs als vensters technisch worden ondersteund, hebben de prestaties van modellen de neiging om na een bepaalde contextlengte achteruit te gaan.
Lange invoer is duur, zelfs met prefix-caching. Je moet nog steeds betalen voor de overdracht en het vooraf invullen per tag.
Om dit probleem op te lossen, implementeren veel agentsystemen contextafkappings- of compressiestrategieën. Maar overmatige compressie leidt onvermijdelijk tot informatieverlies. Het probleem is fundamenteel: de agent moet in wezen zijn volgende zet voorspellen op basis van alle voorgaande toestanden – en je kunt niet op betrouwbare wijze voorspellen welke waarneming tien stappen later van cruciaal belang zou kunnen zijn. Vanuit logisch perspectief is elke onomkeerbare compressie riskant.
Daarom beschouwen we het bestandssysteem als de ultieme context in Manus: oneindig groot, inherent duurzaam en direct bedienbaar door de agent zelf. Het model leert bestanden op verzoek te schrijven en te lezen, waarbij het bestandssysteem niet alleen als opslag wordt gebruikt, maar ook als een gestructureerd extern geheugen.
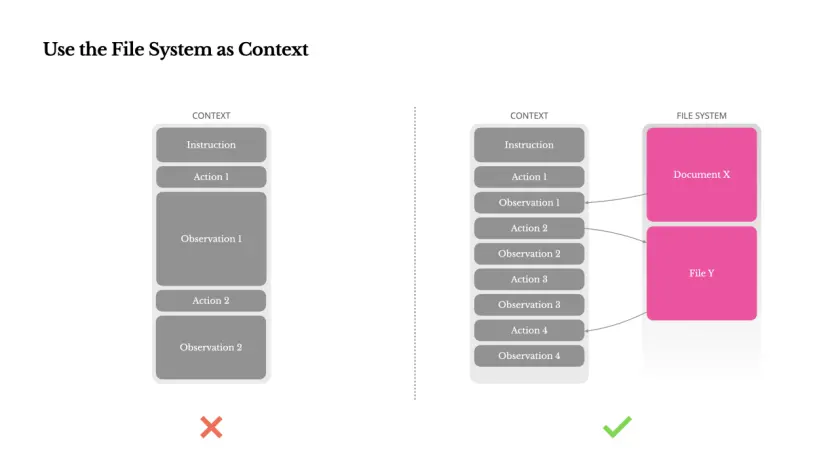
Onze compressiestrategieën zijn altijd ontworpen om herstelbaar te zijn. De inhoud van webpagina's kan bijvoorbeeld uit de context worden verwijderd zolang de URL behouden blijft, en documentinhoud kan worden weggelaten zolang het documentpad in de sandbox blijft. Hierdoor kan Manus de contextlengte inkorten zonder permanent informatie te verliezen.
Tijdens het ontwikkelen van deze functie kon ik me niet anders dan voorstellen wat er nodig zou zijn om een State Space Model (SSM) effectief te laten werken in een agentische omgeving. In tegenstelling tot Transformer ontbeert SSM een volledig aandachtsmechanisme en heeft het moeite met het omgaan met achterwaartse afhankelijkheden over lange afstanden. Maar als ze het op bestanden gebaseerde geheugen onder de knie kunnen krijgen – door de toestand op de lange termijn te externaliseren in plaats van deze in de context te houden – dan zouden hun snelheid en efficiëntie een nieuwe generatie agenten kunnen ontsluiten. De agentachtige SSM kan de echte opvolger zijn van de neurale Turing-machine.
Manipuleer de aandacht door recitatie
Als je Manus hebt gebruikt, heb je misschien een interessant fenomeen opgemerkt: bij het omgaan met complexe taken heeft het de neiging een todo.md-bestand te maken en dit geleidelijk bij te werken naarmate de taak vordert, waarbij de voltooide items worden gecontroleerd.
Dit is niet alleen schattig gedrag, het is een mechanisme om opzettelijk de aandacht te manipuleren.
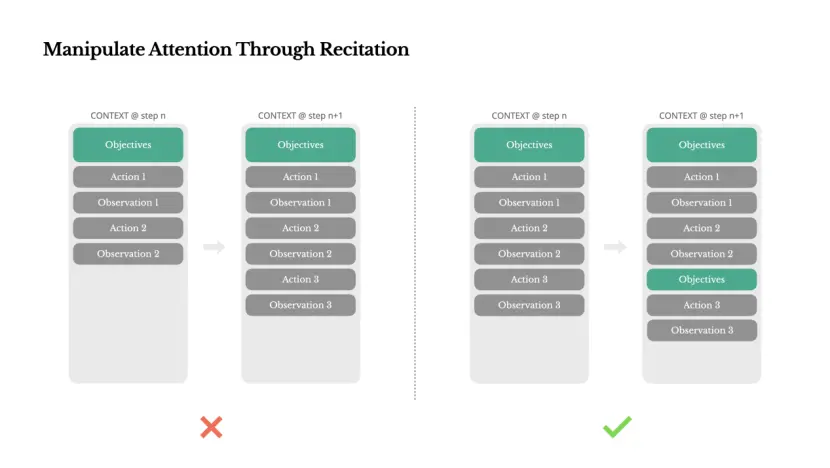
Een typische taak in Manus vereist gemiddeld ongeveer 50 tooloproepen. Dit is een lange lus: aangezien Manus voor de besluitvorming afhankelijk is van LLM's, is het gemakkelijk om van het onderwerp af te wijken of eerdere doelen te vergeten in lange contexten of complexe taken.
Door de to-do-lijst voortdurend te herschrijven, schrijft Manus zijn doelen herhaaldelijk aan het einde van de context. Dit duwt het mondiale plan binnen de aandachtsspanne van het model op de korte termijn, waardoor het ‘lost in the middle’-probleem wordt vermeden en de inconsistentie van doelen wordt verminderd. In feite gebruikt het natuurlijke taal om zichzelf naar taakdoelstellingen te leiden; er zijn geen speciale architectonische veranderingen vereist.
foutmelding behouden
Agenten maken fouten. Dit is geen kwetsbaarheid; het is de realiteit. Taalmodellen kunnen hallucineren, omgevingen kunnen fouten retourneren, externe tools kunnen zich misdragen en onverwachte randgevallen kunnen voortdurend voorkomen. Bij een taak die uit meerdere stappen bestaat, is falen geen uitzondering; het maakt deel uit van de cyclus.
Een algemene impuls is echter om deze fouten te verbergen: ruim de sporen op, probeer de bewerking opnieuw of reset de modelstatus in de hoop op een magische 'temperatuur'-parameter. Dit lijkt veiliger en beter beheersbaar. Maar daar zijn kosten aan verbonden: het wissen van mislukkingen wist het bewijsmateriaal. Zonder bewijs kunnen modellen niet passen.
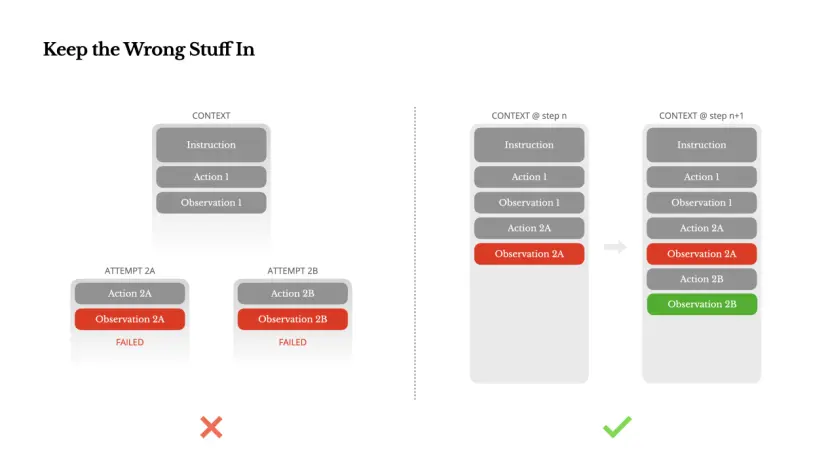
Onze ervaring is dat een van de meest effectieve manieren om het gedrag van agenten te verbeteren bedrieglijk eenvoudig is: gebrekkige paden in hun context houden. Wanneer het model een mislukte bewerking en de daaruit voortvloeiende observatie of stacktrace constateert, werkt het impliciet zijn interne overtuigingen bij. Dit zorgt ervoor dat de prior niet in de buurt komt van soortgelijke operaties, waardoor de kans op herhaling van dezelfde fout wordt verkleind.
Wij zijn zelfs van mening dat foutherstel een van de duidelijkste maatstaven is voor het werkelijke gedrag van agenten. Deze maatstaf wordt echter nog steeds over het hoofd gezien in de meeste academische onderzoeken en publieke benchmarks, die doorgaans gericht zijn op het succespercentage van missies onder ideale omstandigheden.
Laat u niet beperken door een klein aantal voorbeelden
Een paar voorbeeldtips zijn een veelgebruikte techniek om de LLM-uitvoer te verbeteren. Maar in agentsystemen kan het op subtiele manieren averechts werken.
Taalmodellen zijn goed in imitatie; ze repliceren gedragspatronen in context. Als uw context vol is van vergelijkbare actie-observatieparen uit het verleden, zal het model de neiging hebben dit patroon te volgen, zelfs als dit niet langer optimaal is.
Dit kan gevaarlijk zijn bij taken waarbij herhaalde beslissingen of acties betrokken zijn. Als agenten bijvoorbeeld Manus gebruikten om een reeks van twintig cv's te beoordelen, raakten agenten vaak in het ritme van het keer op keer uitvoeren van soortgelijke acties, simpelweg omdat er iets soortgelijks in de context verscheen. Dit kan leiden tot afwijkingen, overgeneralisatie en soms zelfs hallucinaties.
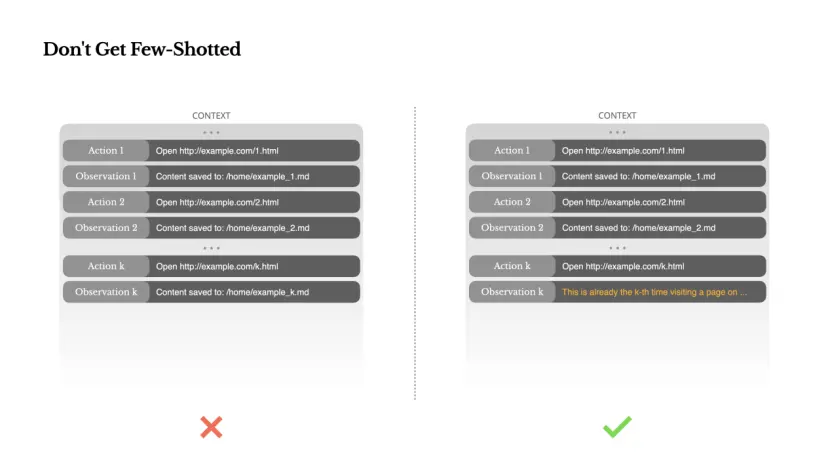
De oplossing is om variatie toe te voegen. Manus introduceert kleine hoeveelheden gestructureerde variatie in acties en observaties: verschillende serialisatiesjablonen, alternatieve uitdrukkingen, subtiele ruis in volgorde of formaat. Deze gecontroleerde willekeur helpt patronen te doorbreken en de focus van het model aan te passen.
Met andere woorden: laat een klein aantal voorbeelden u niet beperken tot een vast patroon. Hoe uniformer de context, hoe kwetsbaarder de agent.
tot slot
Contextuele engineering is nog steeds een opkomende wetenschap, maar voor agentsystemen is het nu al cruciaal. Modellen kunnen krachtiger, sneller en goedkoper worden, maar geen enkele hoeveelheid brute kracht kan de behoefte aan geheugen, context en feedback vervangen. Hoe je de context vormgeeft, bepaalt uiteindelijk hoe de agent zich gedraagt: hoe snel hij werkt, hoe veerkrachtig hij is en hoe ver hij schaalt.
Bij Manus hebben we deze lessen geleerd door herhaalde herschrijvingen, doodlopende wegen en praktijktesten met miljoenen gebruikers. Wat we hier delen zijn geen universele waarheden, maar dit zijn patronen die voor ons hebben gewerkt. Als ze je helpen zelfs maar één pijnlijke herhaling te vermijden, dan heeft dit artikel zijn doel gediend.
De toekomst van intelligente agenten zal stap voor stap worden opgebouwd, van scenario tot scenario. Creëer elke situatie zorgvuldig.